Processing Data¶
Lemmatization, Language Detection and Named Entity Recognition (MLP)¶
You can use MLP (the MultiLingual Preprocessor) to preprocess data.
MLP can process multiple languages, lemmatize, extract named entities etc.
MLP can be applied to individual text or to indices.
Running MLP can be a long task, depending on the amount of analyzers chosen and amount and length of the documents. For processing a lot of documents at once, use the MLP Python module (https://pypi.org/project/texta-mlp/).
To use MLP in the Bwrite Toolkit, open up the Tools menu and pick MLP.
Press Create to create a new process for processing an index or indices or Apply to text to test out MLP on some sentences.
Analyzers¶
When creating an MLP task or applying to text, analyzers are where you’ll choose how your document(s) are processed.
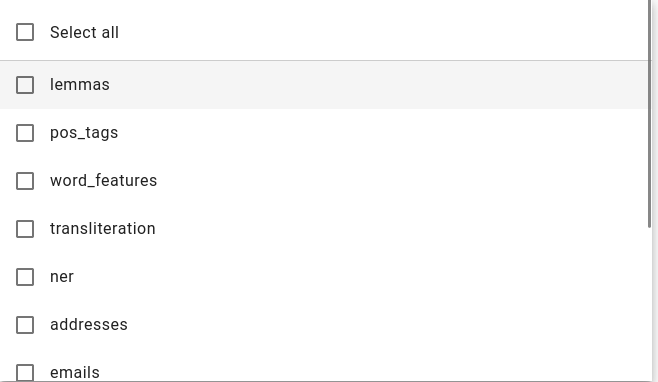
You can choose one or multiple analyzers to apply at once.
lemmas - lemmatizes the document (turns all the words in the document into dictionary variants of the word)
pos_tags - adds Part-of-Speech tags to the document
word_features - adds more linguistic information about each word in the document
transliteration - adds a representation of some languages (Russian, Arabic) in the latin alphabet
ner - extracts named entities (people’s names, organizations etc) from the document (applied as facts)
addresses - automatically detects addresses in the document as facts
emails - automatically detects email links in the document as facts
phone_strict - automatically detects phone numbers in the document as facts
entities - extracts entities from documents based on keywords
currency_sum - extracts currencies from the document as facts
sentences - separates the text into sentences automatically (for example, for found named entities, adds the sentence information into generated facts)
Creating an MLP task (to apply on an index)¶
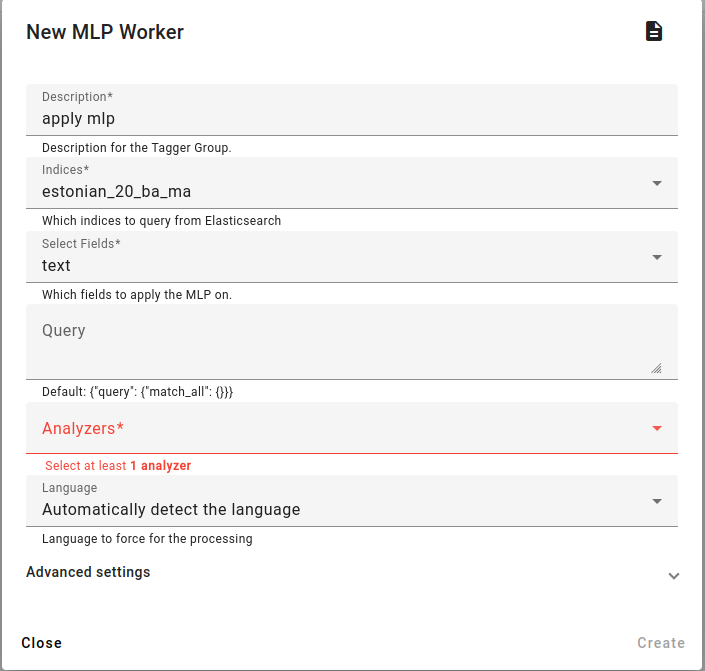
When creating an MLP task, fill in the description, select the indices and fields to analyze.
For any index you choose, be aware that applying MLP will add extra fields to the index based on the analyzers chosen.
You have the option of choosing a subset of an index by using a query.
Then choose the Analyzers.
You also have the choice of automatically detecting the language of the processed documents or preselecting the language from the Language drop-down menu.
After filling everything in, press Create to create the task. To monitor the progress of this task, refresh the page. After the task is completed, you can reload your index and see the new information that was added.
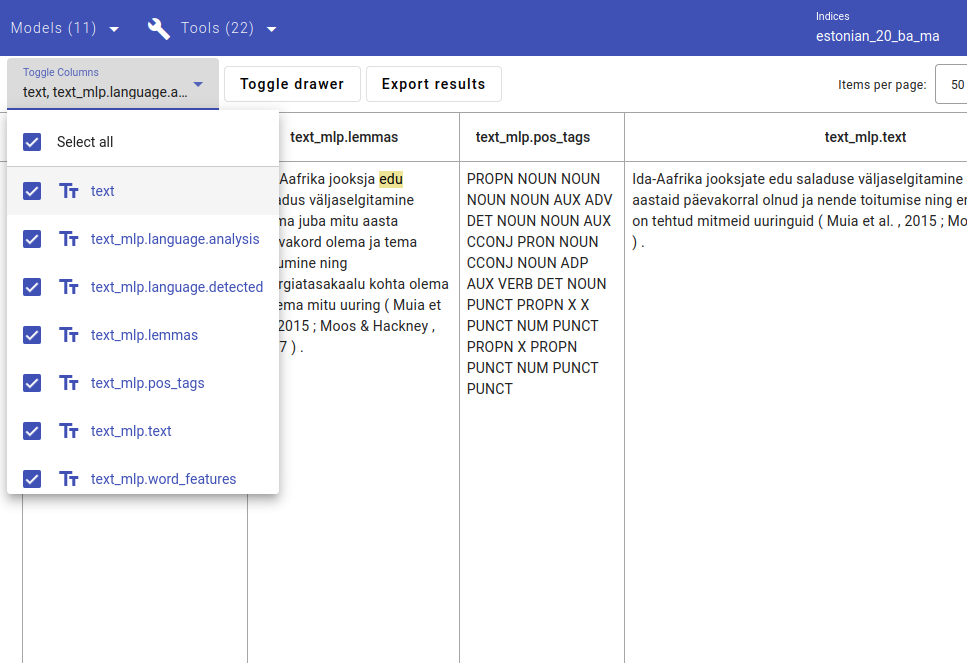
The index used to only have the fields text and texta_facts, new fields have been added by MLP as you can see from the Toggle columns drop-down menu in the search view. All the new fields have text_mlp in their names.
Applying MLP on an individual document¶
To apply MLP on an individual text, click on Apply to text.

A new window will appear where you can enter in your text and choose the analyzers.
Example text used from BBC:

Enter the text you wish to analyze and select the Analyzers you wish to use.
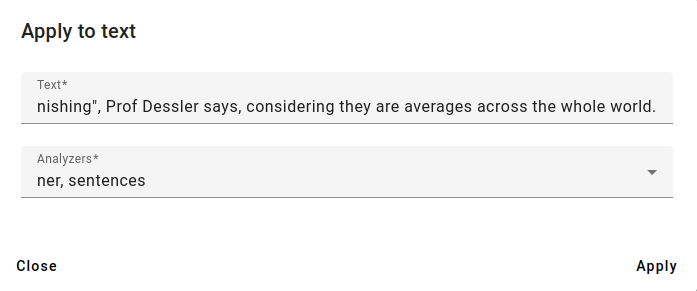
For this example, we select the analyzers ner and sentences to find named entities.
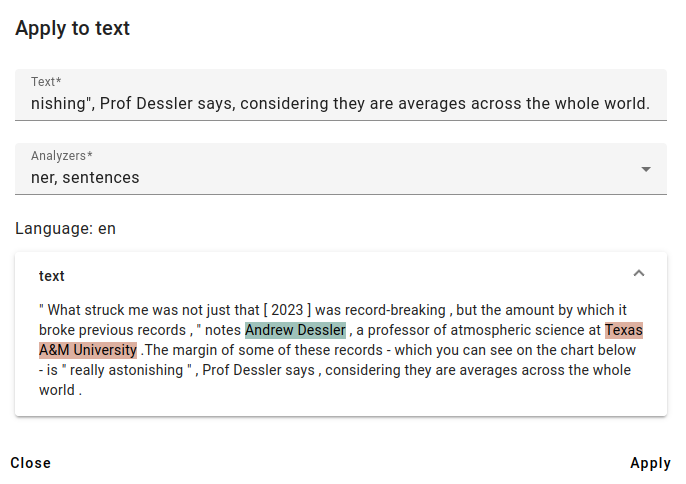
The results show that MLP has correctly detected the input language as English and found two named entities.
A third entity (Dessler in the part Prof Dessler says) has remained undetected, since automatic named entity detection can have errors or miss entities.
You can get more information about the entities by hovering your cursor over the highlighted areas of the text.
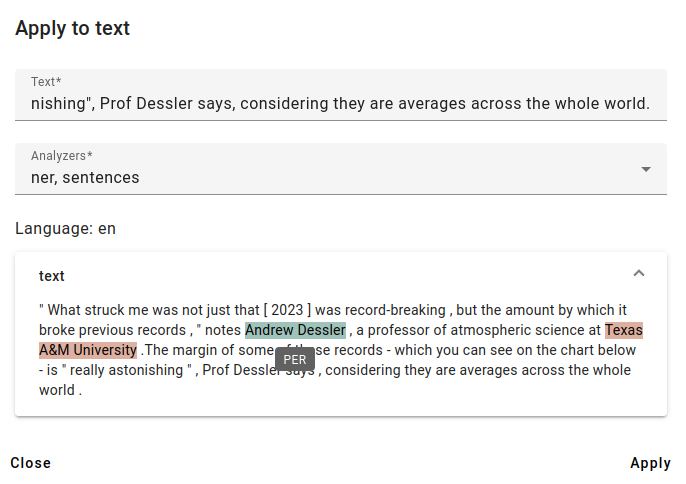
One of the found entities is a person’s name (with the label PER): Andrew Dessler.
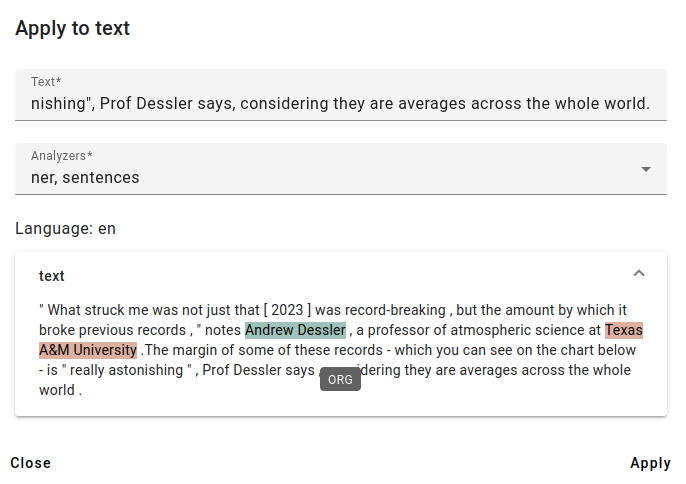
And the other found entity is an organization (with the label ORG): Texas A&M University.
Language Detection¶
For just detecting the language of documents without any further processing, use the Language Detector in the Tools menu.
It can also be helpful to use in case you have a large corpus with unknown language composition.
Similarly to MLP, you can click on Create to apply the language detector on an index or indices or use the Apply to text button to test it on an individual text.
For the Language Detector task fill in the description and choose the indices.
You can select the text fields where you wish to detect the language.
You can also apply a query here for a subset of documents.
Then click Create to create the Language Detector task.
Apply to text works similarly to the MLP Apply to text example.
Tokenizing, Stemming and Stripping HTML (ES Analyzer)¶
Maybe there is some weird HTML in your documents or you want to try finding all the word stems in a document.
For this, open up the Tools menu and click on ES Analyzer. ES Analyzer refers to Elasticsearch analyzer.

Click on Create to apply the analyzer on an index. To find all the word stems in an individual document, press Apply stemmer to text.
For analyzing indices, fill in the description, choose the indices and select the fields to parse content from.
You can also use a query here if you wish.
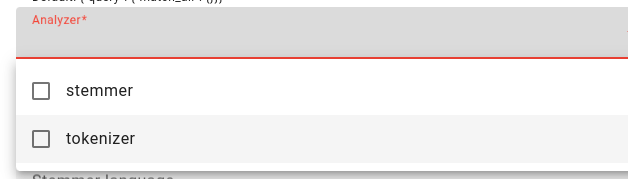
Then choose the analyzer(s): stemmer, tokenizer or both.
The stemmer finds word stems, and the tokenizer tokenizes the document/text.
Choose which tokenizer to use and the stemmer language if doing a stemming task (Estonian and Lithuanian are options).
You can also use language detection in this task if you have documents in different languages.
If you want to get rid of unnecessary HTML, then pick the Strip HTML option.
An example of tokenization and stemming using the standard tokenizer on data:

Below is an example of applying the stemmer to text from ERR (https://www.err.ee/1609216546/euroopa-komisjon-soovib-karmistada-kasside-ja-koerte-pidamise-noudeid).
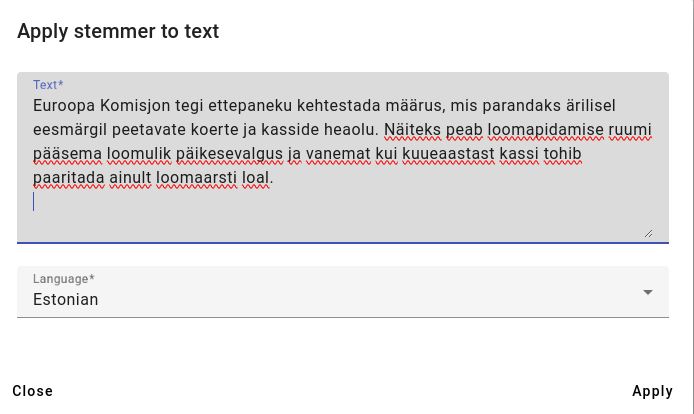
The results of using the stemmer:

Tokenizer options¶
Tokenizer options are options that allow you to choose the method of tokenizing in ES Analyzer.

The keyword tokenizer outputs the exact same text as a single term.
The standard tokenizer divides text into terms on word boundaries and removes most punctuation symbols. It is the best choice for most languages.
The letter tokenizer divides text into terms whenever it encounters a character which is not a letter.
The lowercase tokenizer divides text into terms whenever it encounters a character which is not a letter, but it also makes all terms into lowercase.
The whitespace tokenizer divides text into terms whenever it encounters any whitespace character.
The uax_url_email tokenizer is like the standard tokenizer except it recognises URLs and email addresses as single tokens.
Classic (English) and thai (Thai) are language-specific tokenizers.