Bwrite Corpus Overview¶
Accessing Data in Original Form¶
To access the data in original form (whole documents) with metadata, choose project 7: Final corpora (whole documents).
The data is separated by language into Estonian, Latvian and Lithuanian indices.
Corpus language |
Index name |
Number of documents |
|---|---|---|
Estonian |
year_documents_et |
34 701 |
Latvian |
year_documents_lv |
3773 |
Lithuanian |
year_documents_lt |
43 336 |
To access these indices, see Projects and Indices.
Metadata information for original documents¶
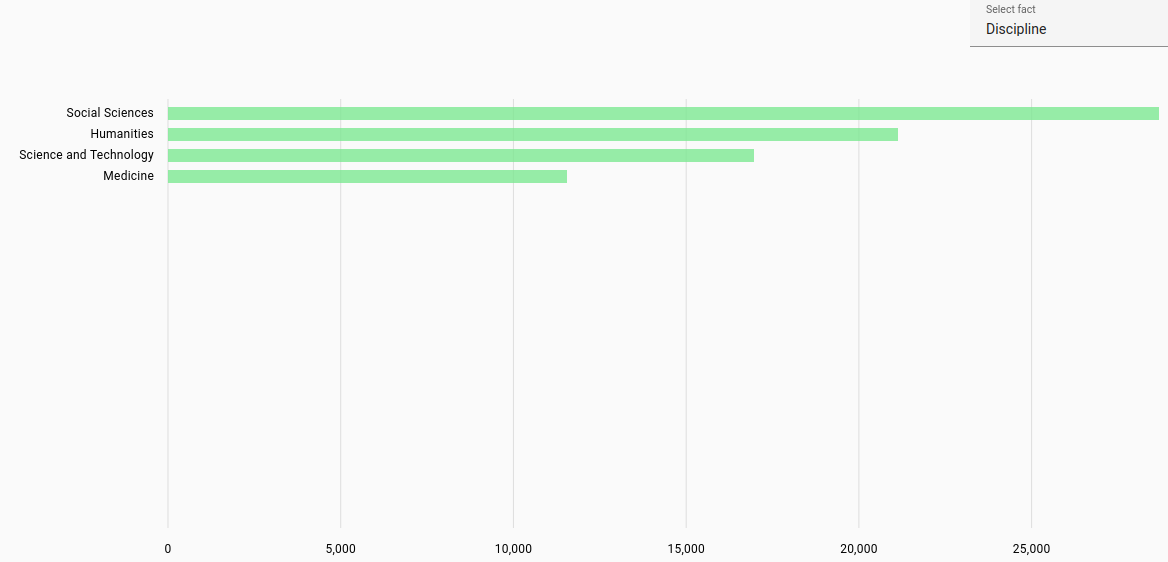
Disciplines: Most frequent disciplines for documents, automatically parsed from faculty names/journal names etc.
A few documents have two disciplines due to having two faculties. Some documents have no discipline, due to being unable to parse the necessary data from the document contents/metadata.
Due to automatic parsing there may be inaccuracies.
Corpus language |
Humanities |
Medicine |
Science and Technology |
Social Sciences |
|---|---|---|---|---|
Estonian |
6751 |
4035 |
9589 |
12 811 |
Latvian |
1453 |
432 |
711 |
818 |
Lithuanian |
12 952 |
7101 |
6683 |
15 058 |
Sum |
21 156 |
11 568 |
16 983 |
28 687 |
Overall disciplines distribution across all languages:
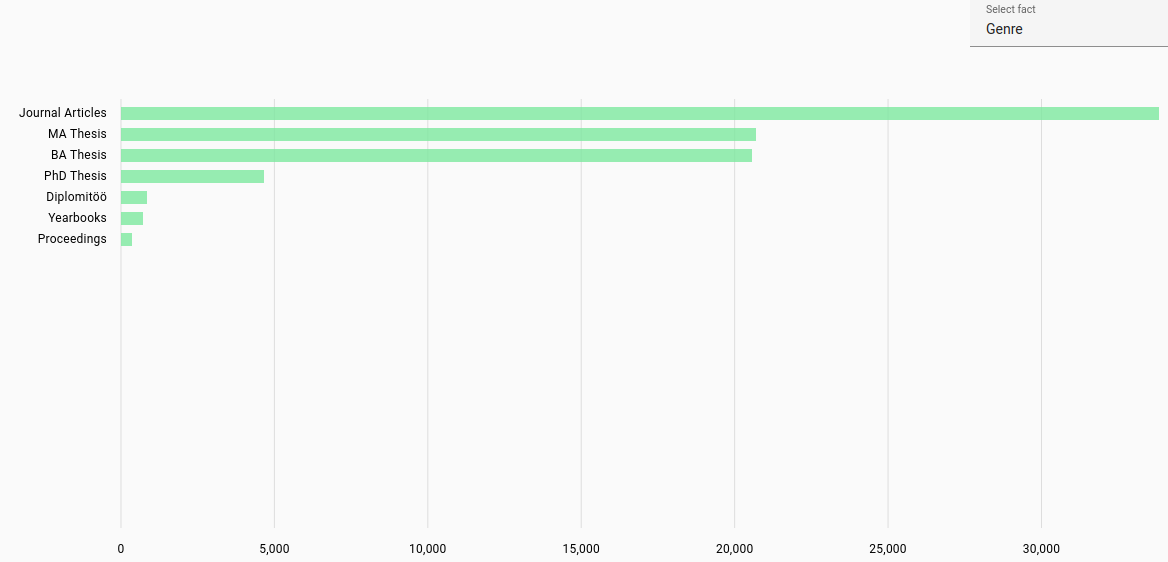
Genres: Most frequent genres in corpus (parsed from original metadata).
Corpus language |
BA thesis |
MA thesis |
PhD thesis |
Other student work |
Journal Articles |
Proceedings |
Yearbooks |
|---|---|---|---|---|---|---|---|
Estonian |
16 215 |
9380 |
1170 |
870 |
6199 |
134 |
733 |
Latvian |
153 |
2 |
1634 |
0 |
1737 |
247 |
0 |
Lithuanian |
4229 |
11 331 |
1882 |
0 |
25 894 |
0 |
0 |
Sum |
20 597 |
20 713 |
4686 |
870 |
33 830 |
381 |
733 |
Overall genres distribution across all languages:
Publication year: Most frequent publication year for student work or journal article (automatically parsed).
The publication year was determined for the years 1900-2023. Due to automatic parsing there may be inaccuracies.
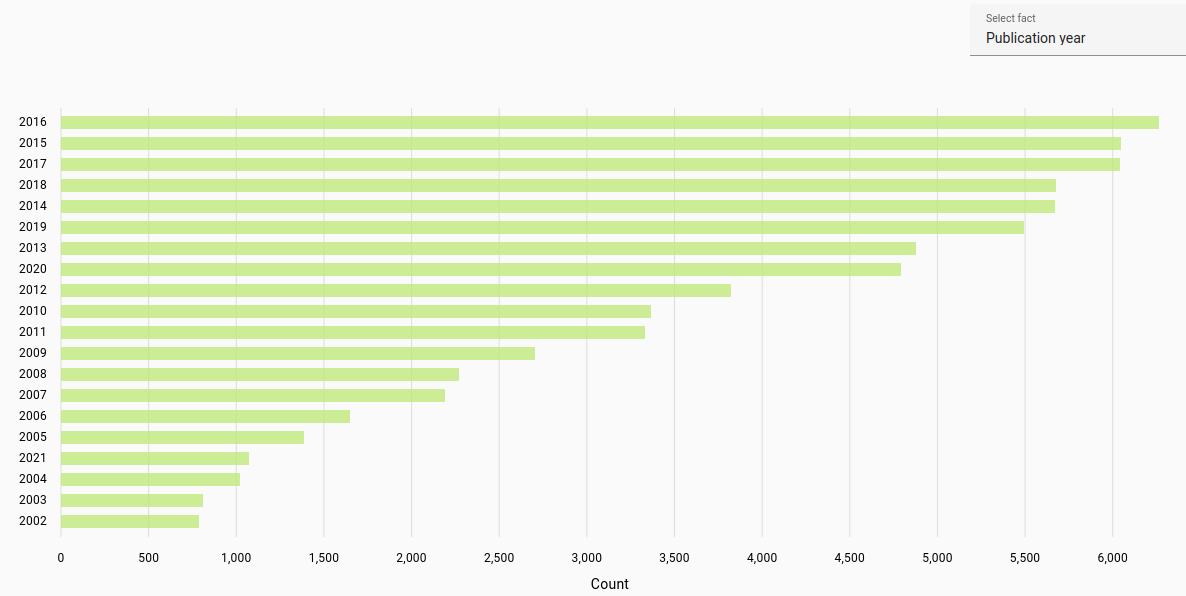
All documents
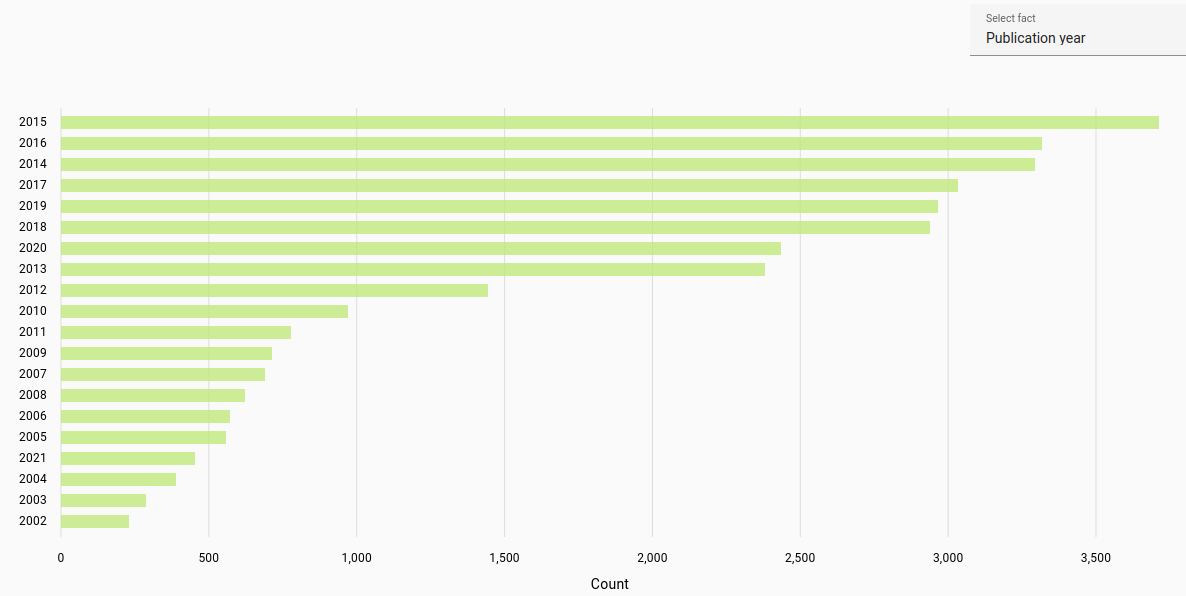
Estonian documents
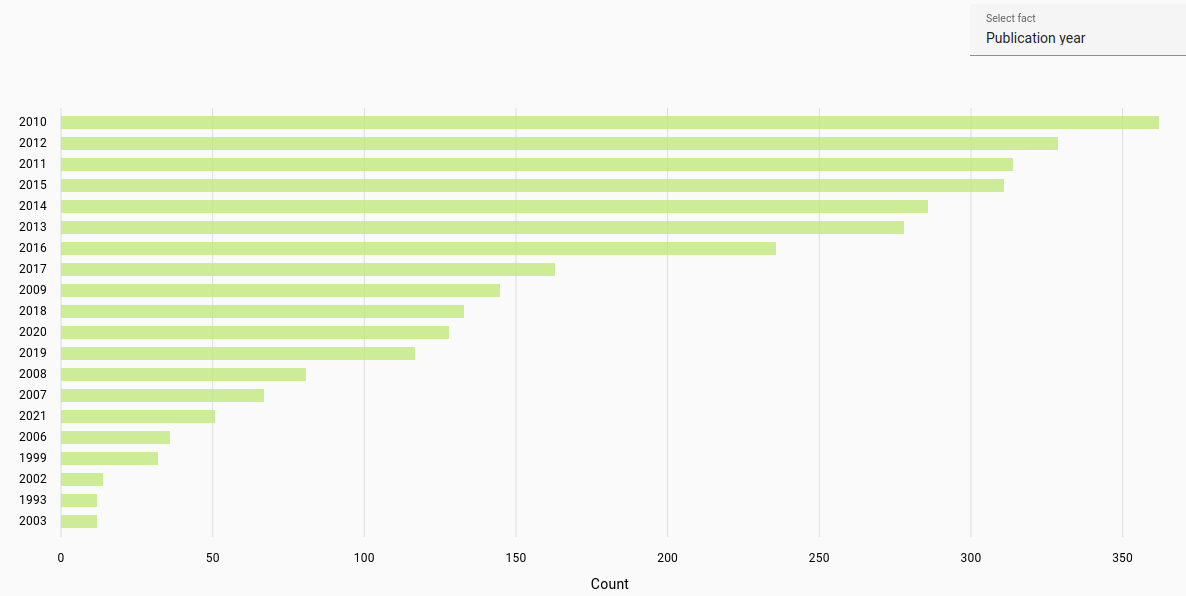
Latvian documents
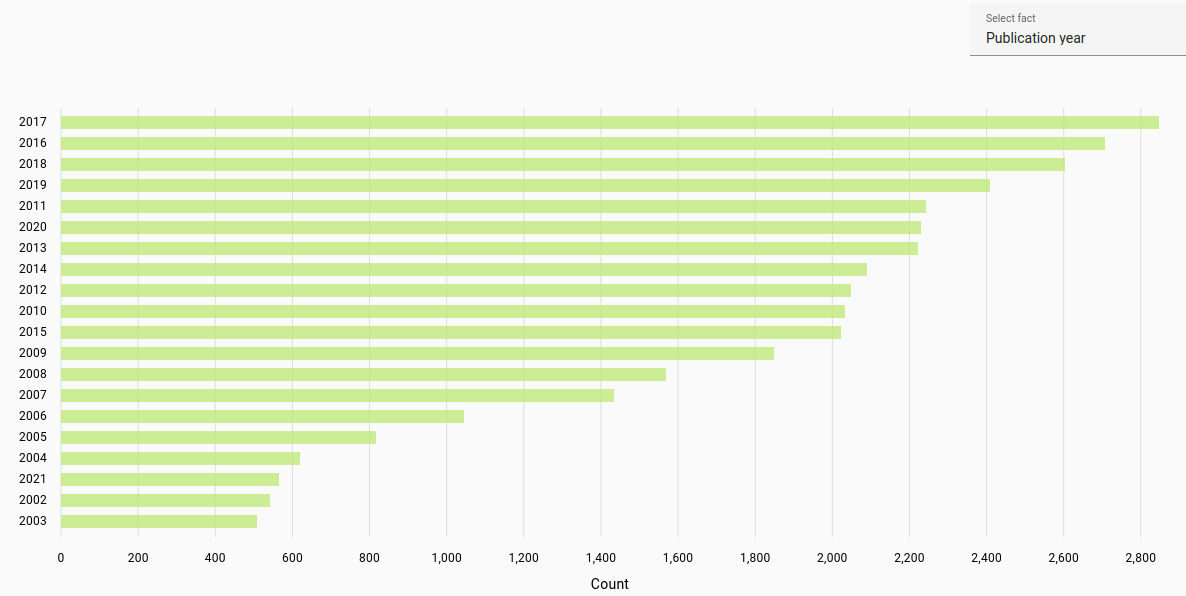
Lithuanian documents
Universities: Most frequent universities found for student work in each language.
For Estonian and Latvian, automatically extracted from file path in NextCloud, while Lithuanian was automatically parsed from the title page of theses. Due to automatic parsing there may be inaccuracies.
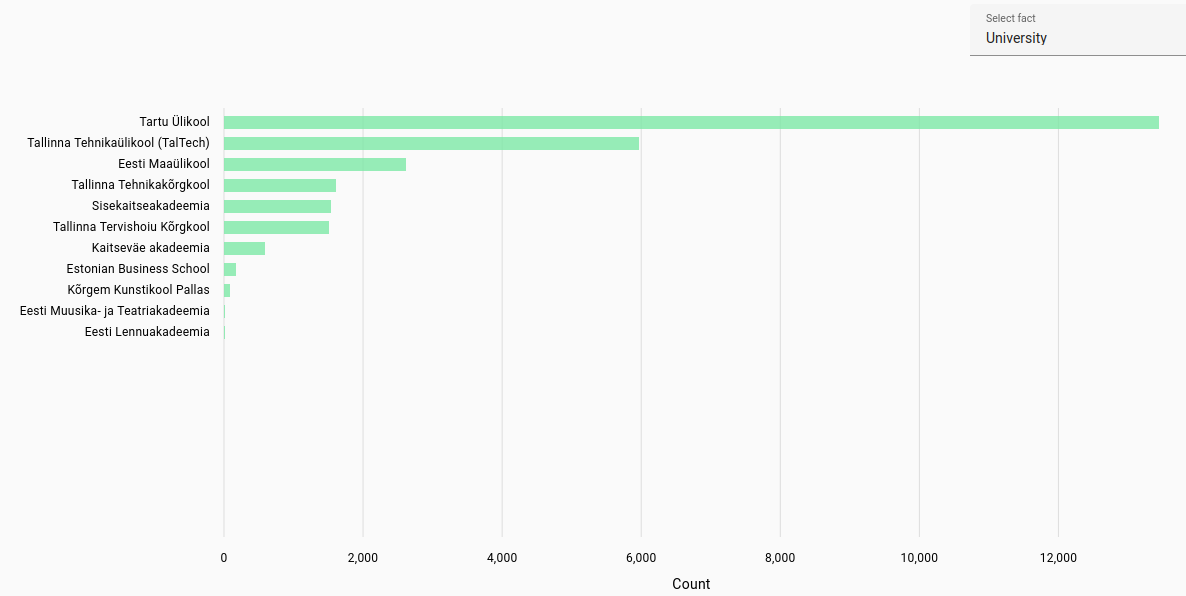
Estonian universities
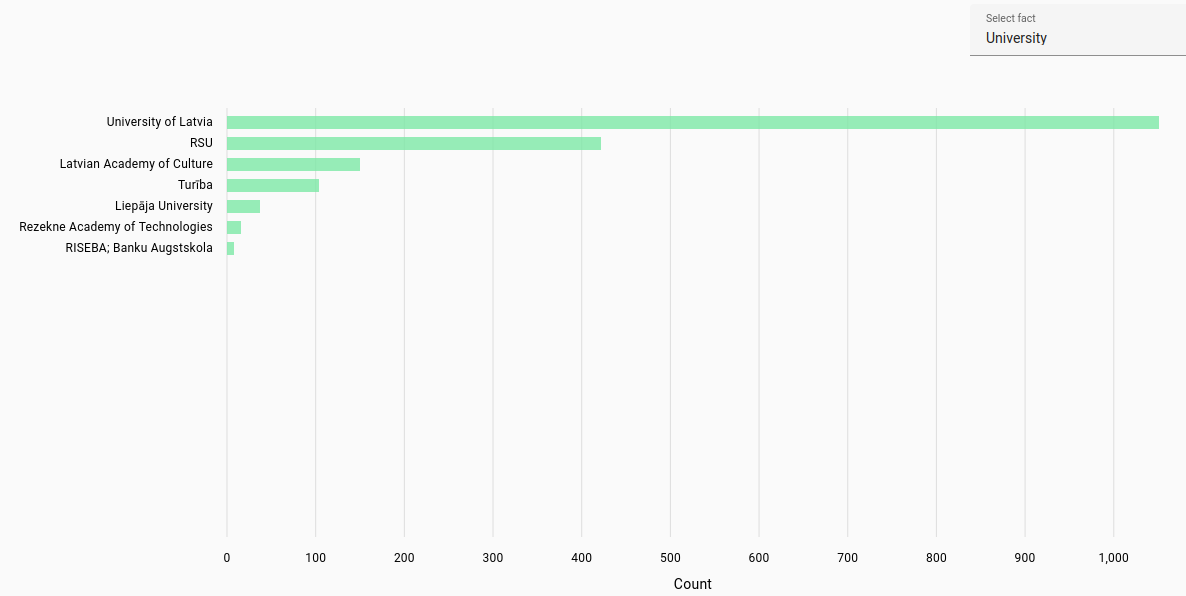
Latvian universities
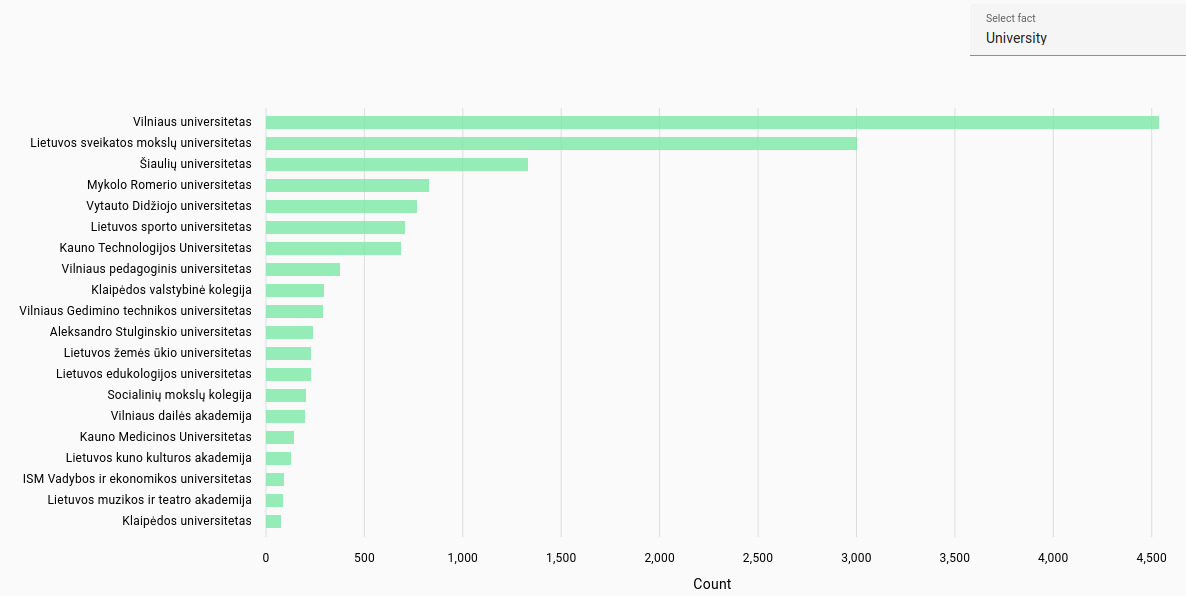
Lithuanian universities
Publications: Most frequent publications found for journal articles in each language. Automatically extracted from file path in NextCloud.
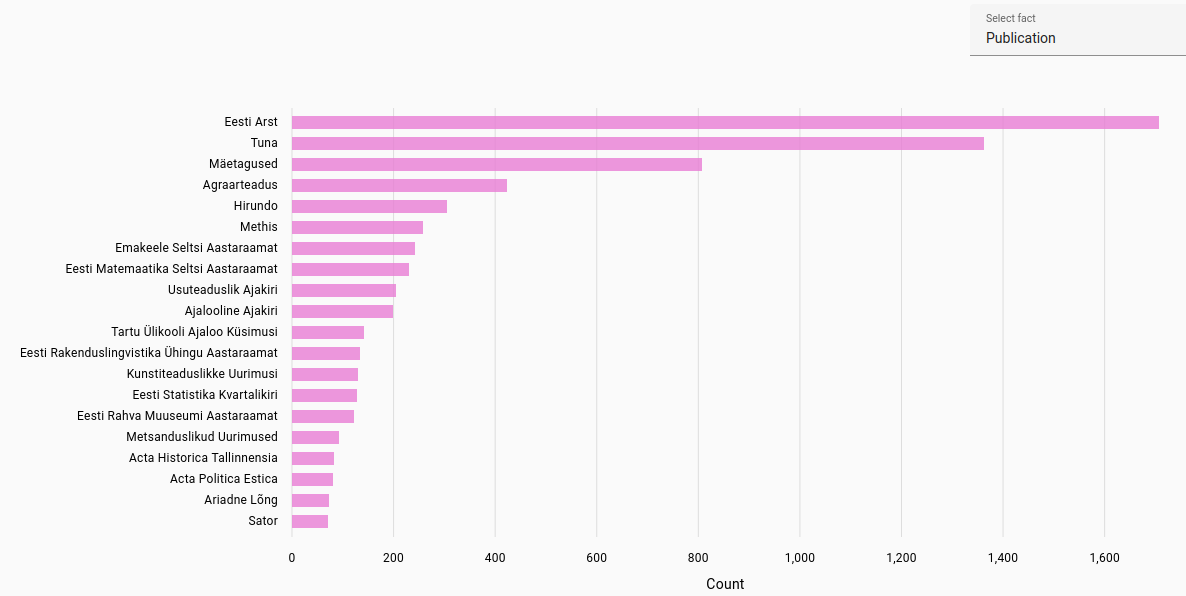
Estonian publications
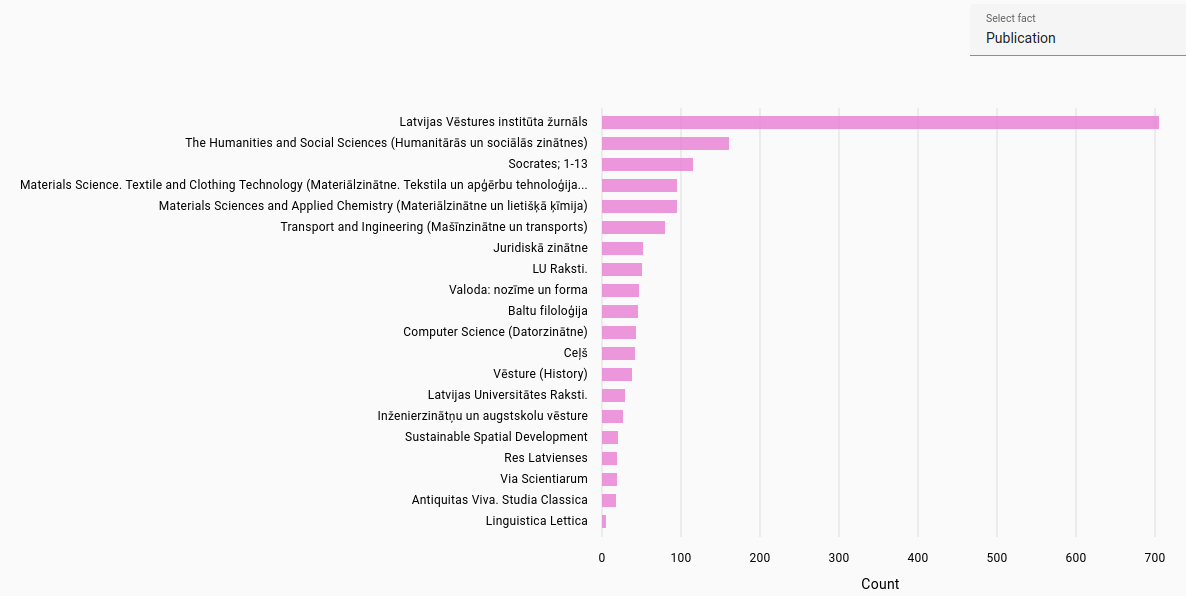
Latvian publications
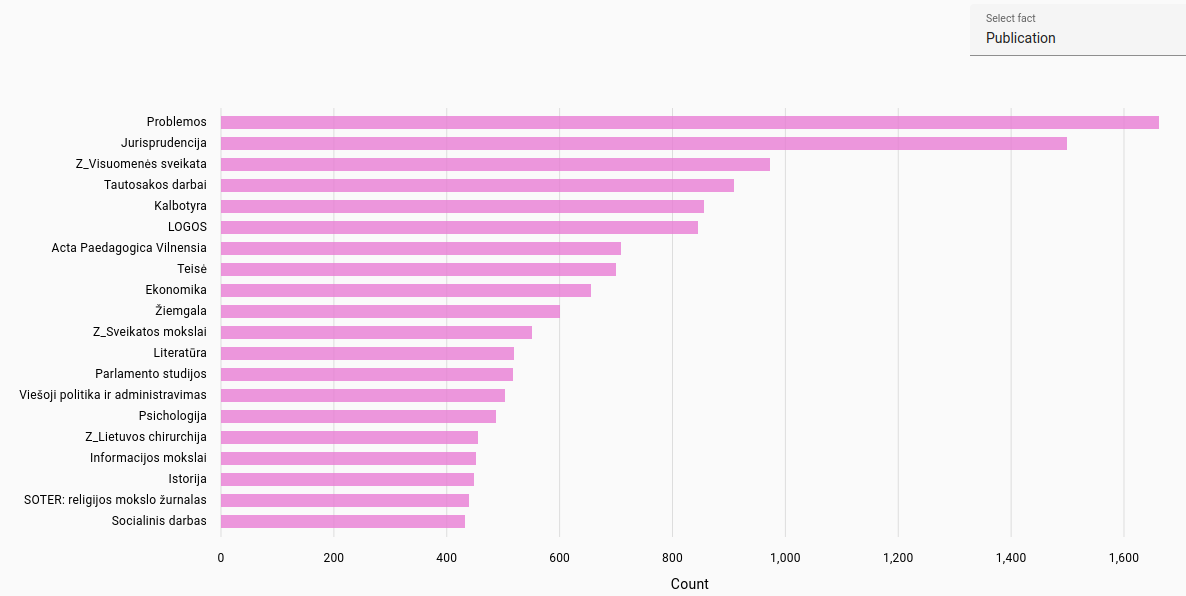
Lithuanian publications
Accessing Data in Sentences¶
To access the data in sentence form (where the original documents have been split into sentences) with metadata, choose project 8: Final corpora (sentences).
The data is separated by language into Estonian, Latvian and Lithuanian indices.
Corpus language |
Index name |
Number of documents |
|---|---|---|
Estonian |
year_documents_et_split2 |
27 816 000 |
Latvian |
year_documents_lv_split |
4 673 416 |
Lithuanian |
year_documents_lt_split |
26 471 018 |
To access these indices, see Projects and Indices.
Metadata information for sentences¶
Disciplines: Most frequent disciplines for documents split into sentences, automatically parsed from faculty names/journal names etc.
A few documents have two disciplines due to having two faculties. Some documents have no discipline, due to being unable to parse the necessary data from the document contents/metadata.
Due to automatic parsing there may be inaccuracies.
Corpus language |
Humanities |
Medicine |
Science and Technology |
Social Sciences |
|---|---|---|---|---|
Estonian |
4 905 206 |
1 751 448 |
6 473 543 |
13 855 932 |
Latvian |
1 323 767 |
531 757 |
699 703 |
1 910 699 |
Lithuanian |
5 254 793 |
4 695 374 |
4 750 700 |
10 599 823 |
Sum |
11 483 766 |
6 978 579 |
11 923 946 |
26 366 454 |
Overall disciplines distribution across all languages:
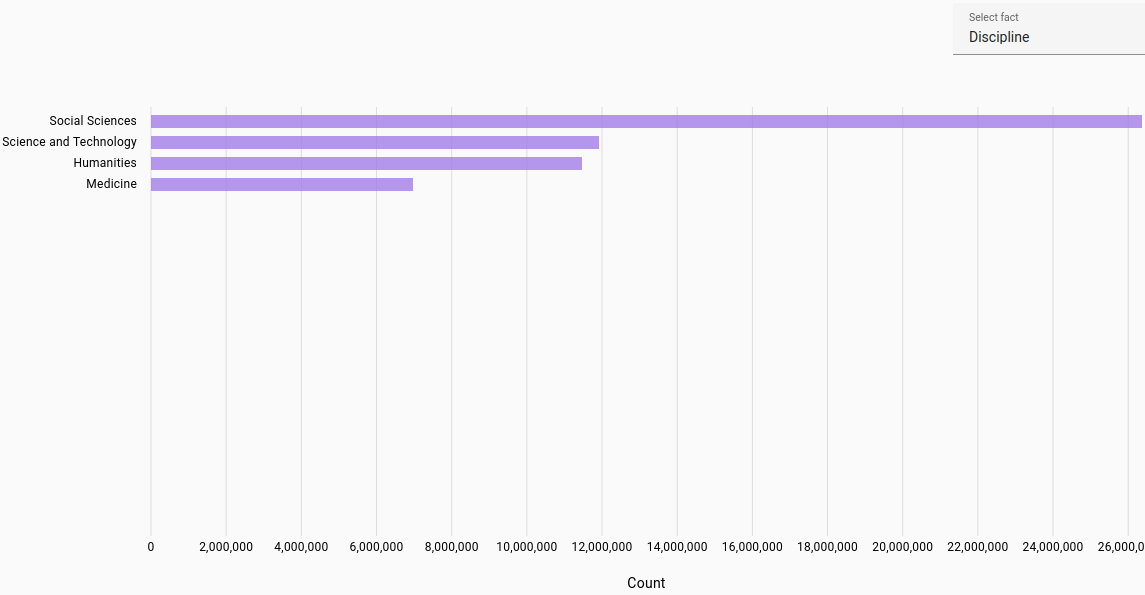
Genres: Most frequent genres in corpus (parsed from original metadata).
Corpus language |
BA thesis |
MA thesis |
PhD thesis |
Other student work |
Journal Articles |
Proceedings |
Yearbooks |
|---|---|---|---|---|---|---|---|
Estonian |
12 745 043 |
10 250 258 |
2 496 556 |
575 682 |
1 581 241 |
15 620 |
224 709 |
Latvian |
222 962 |
3641 |
3 879 790 |
0 |
529 848 |
37 175 |
0 |
Lithuanian |
3 486 868 |
11 596 723 |
3 951 484 |
0 |
7 435 943 |
0 |
0 |
Sum |
16 454 873 |
21 850 622 |
10 327 830 |
575 682 |
9 547 032 |
52 795 |
224 709 |
Overall genres distribution across all languages:
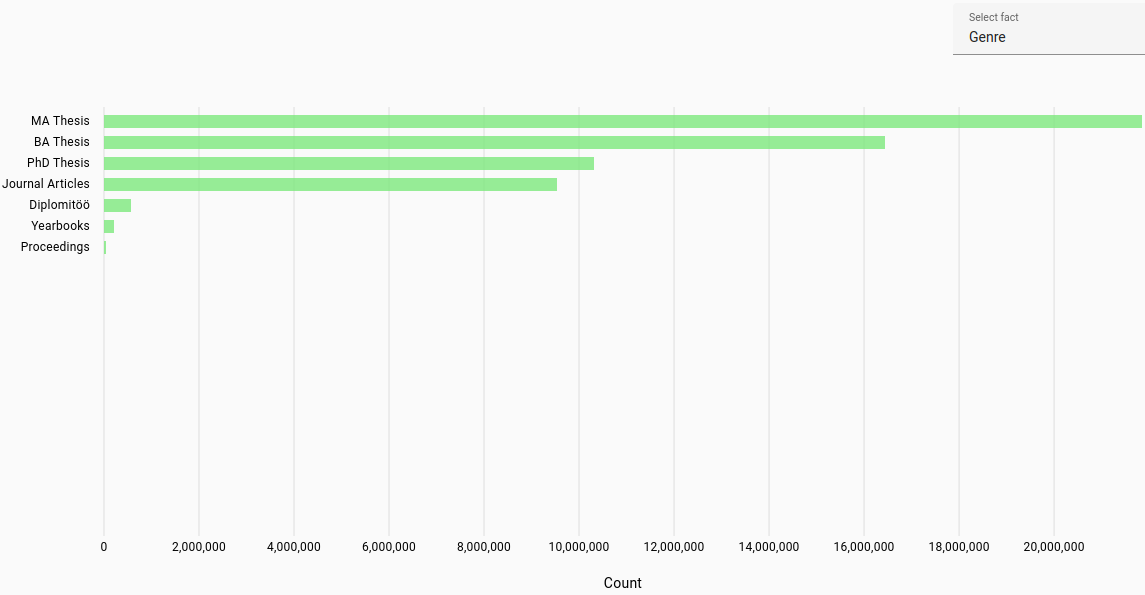
Publication year: Most frequent publication year for student work or journal article (automatically parsed).
The publication year was determined for the years 1900-2023. Due to automatic parsing there may be inaccuracies.
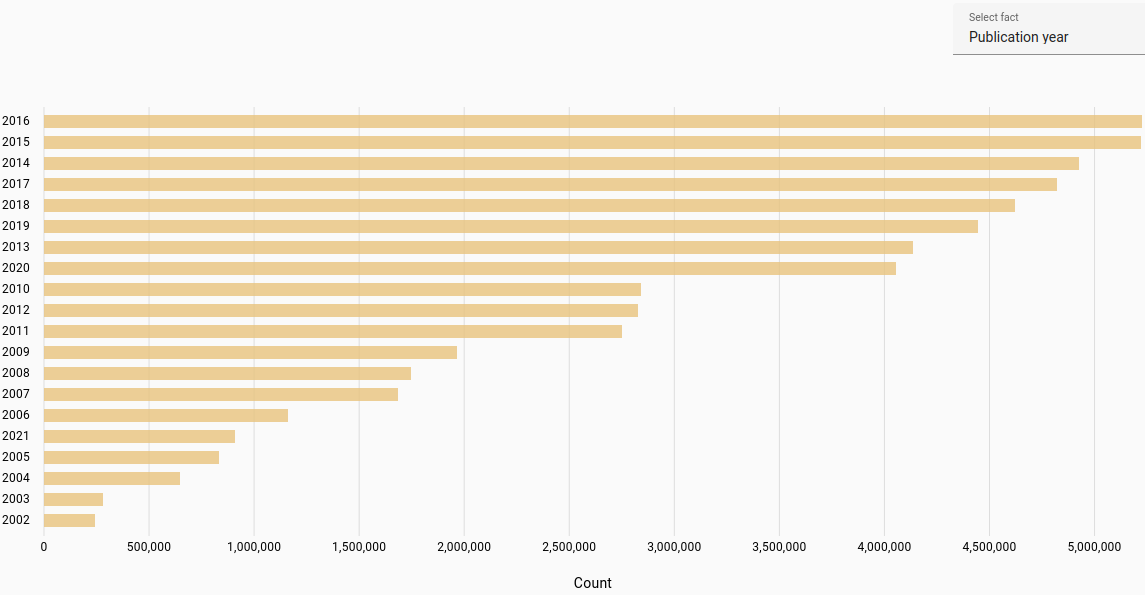
All documents
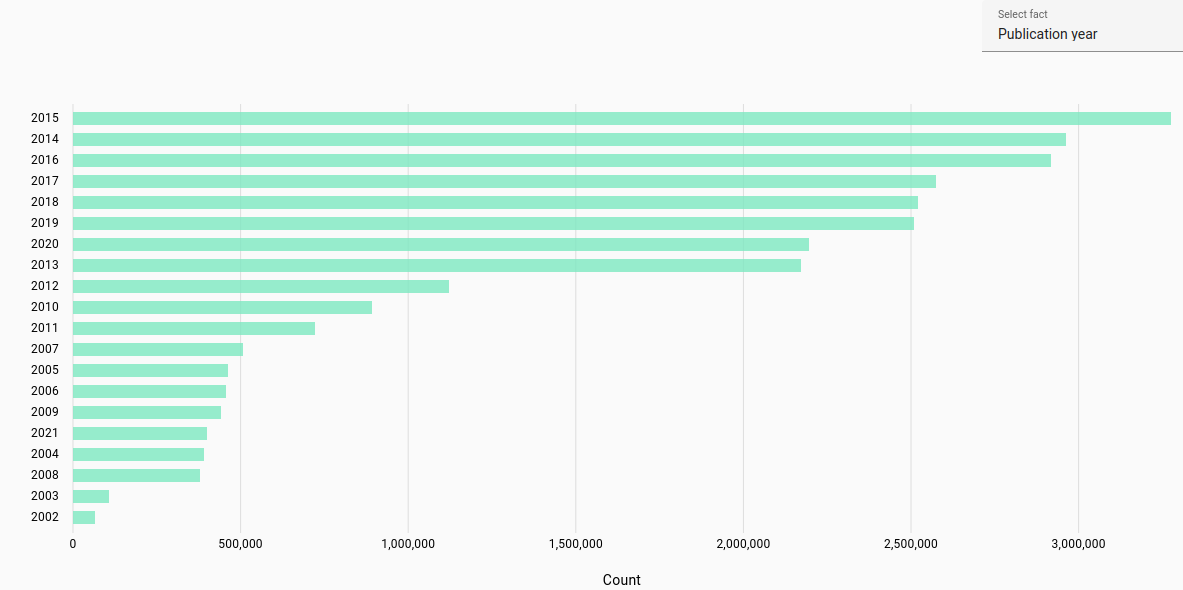
Estonian documents
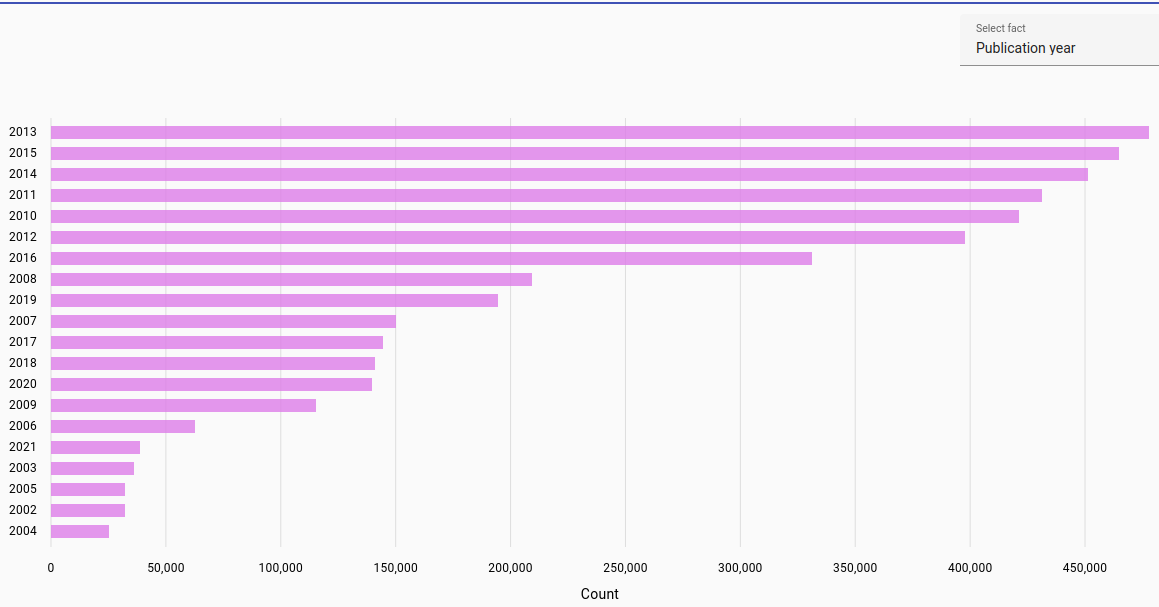
Latvian documents
Lithuanian documents
Universities: Most frequent universities found for student work in each language.
For Estonian and Latvian, automatically extracted from file path in NextCloud, while Lithuanian was automatically parsed from the title page of theses. Due to automatic parsing there may be inaccuracies.
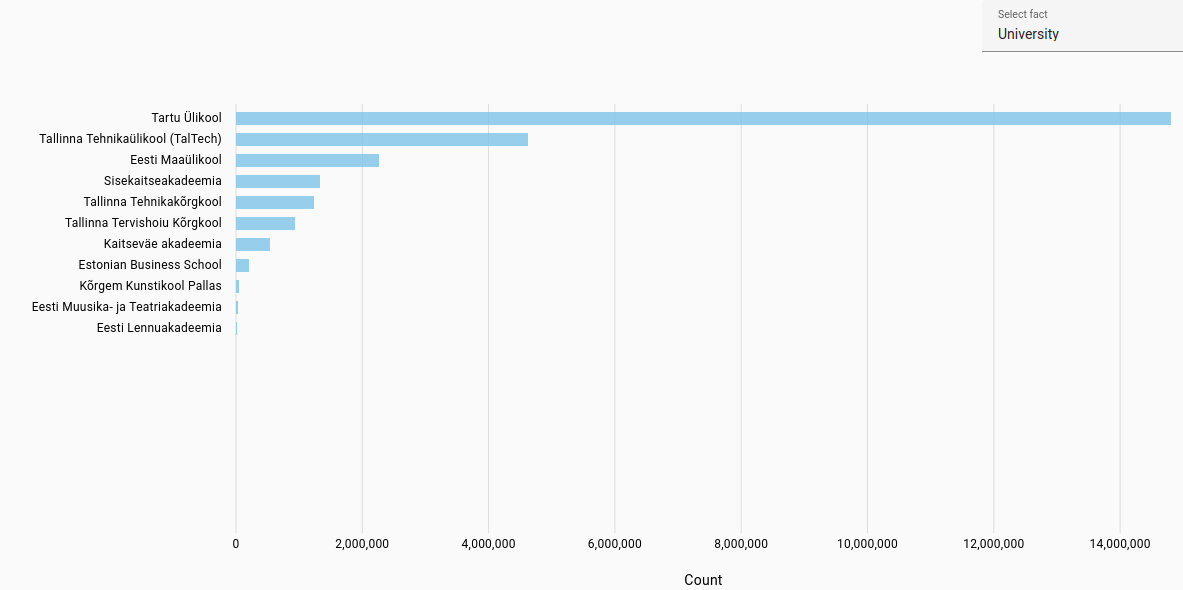
Estonian universities
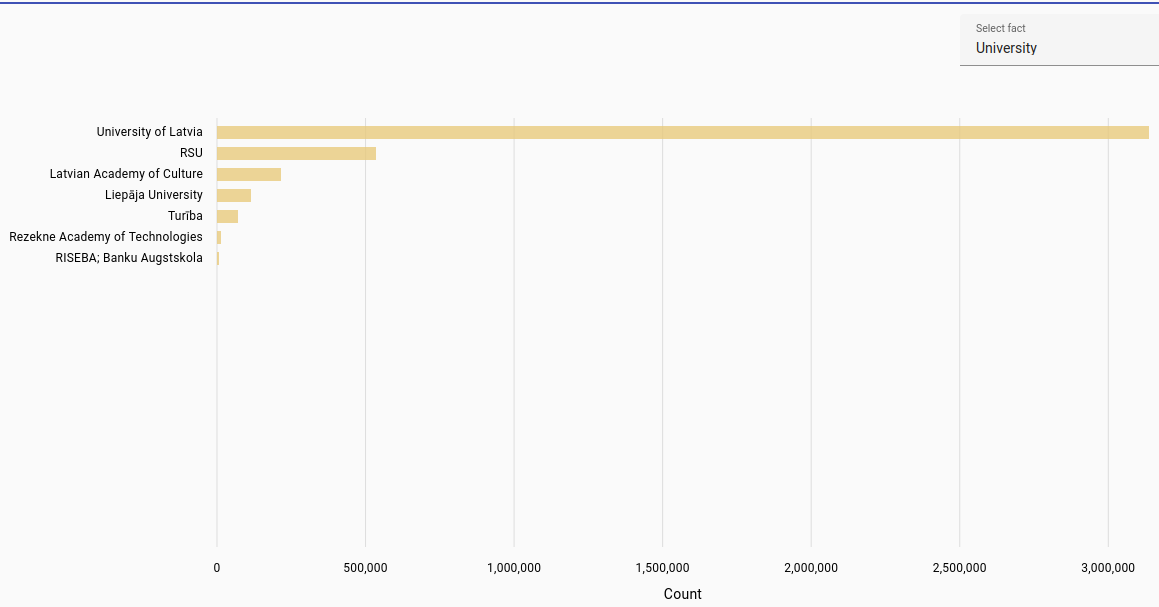
Latvian universities
Lithuanian universities
Publications: Most frequent publications found for journal articles in each language. Automatically extracted from file path in NextCloud.
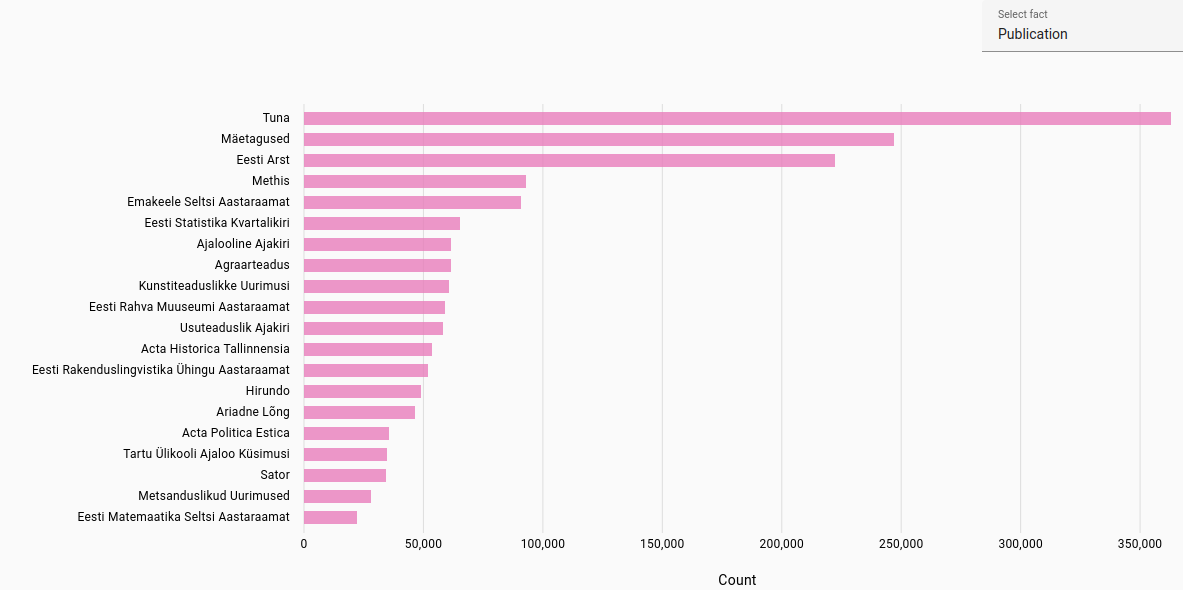
Estonian publications
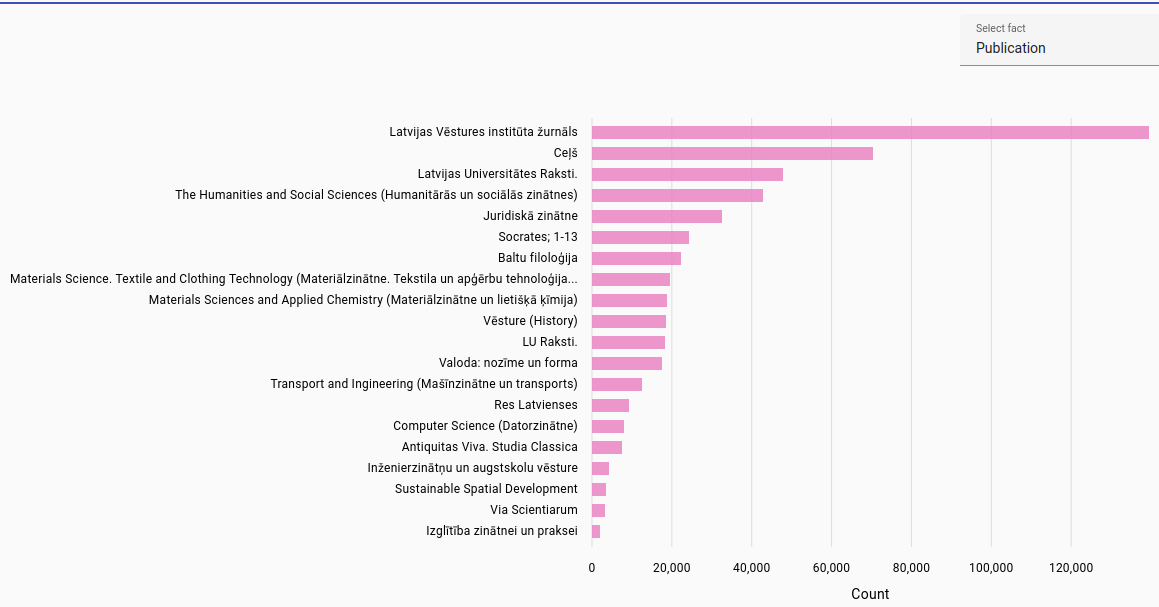
Latvian publications
Lithuanian publications
How to find the same document in full or in sentences¶
Let’s say you have a document or documents you are interested in. You can find out the documents’ meta.file values and use that for searching for the same document in a different form.
For example, for the demo project, 20 random documents from all languages have been extracted for testing purposes.
But what if you need those documents in sentences?
Consider creating a query for getting only the files you are interested in. In this case, we have 20 documents, which should not be too much.
We can aggregate the query by selecting the field meta.file to get all of the file names.
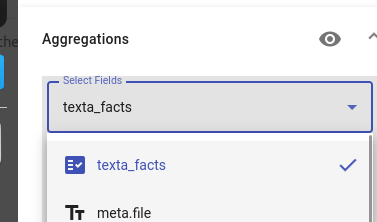
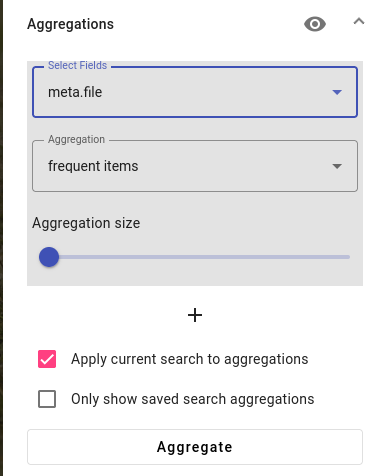
Press Aggregate to see the results.
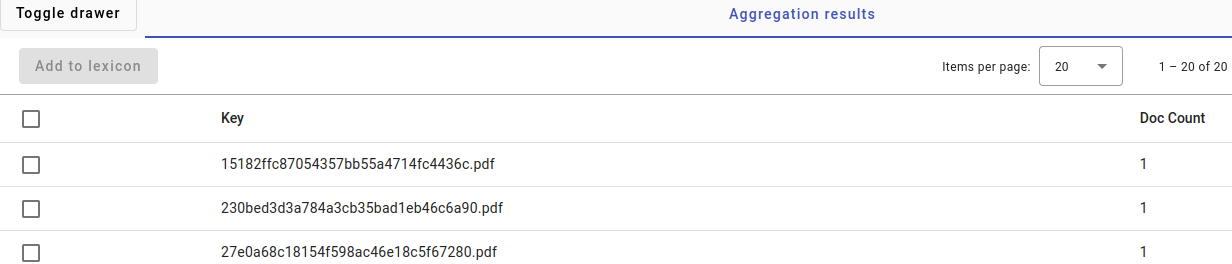
Here are the results. Pay close attention to the items per page on the right. If you should have more than 20 results, then choose a larger number to display.
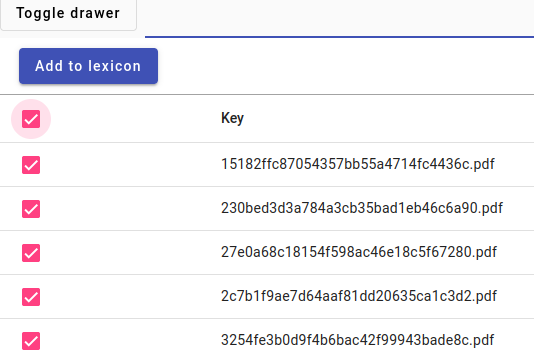
We can automatically select all of the filenames to put in a lexicon by ticking the uppermost box in the picture, next to the word Key.
Then press Add to lexicon.
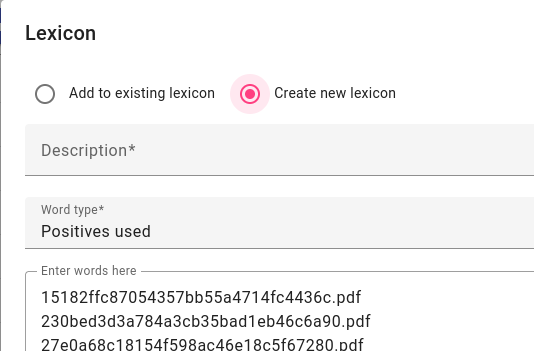
A menu will appear where you can either overwrite an existing lexicon or create a new one. Choose the description/name and if you want to use the lexicon for a search later, then choose the word type as Positives used.
Navigate to the sentences version of the same index. In this example, we’re searching for Lithuanian documents, so we choose year_documents_lt_split2 to search for the same documents in sentences.
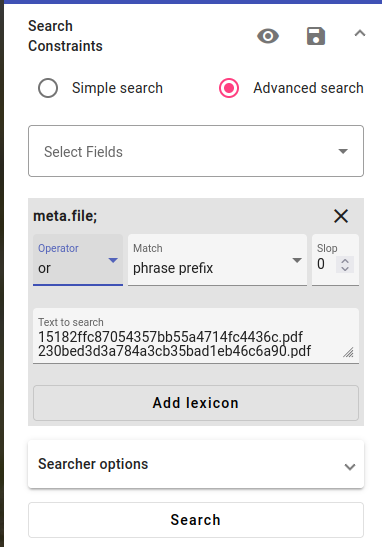
You can use the lexicon for a query and get the same documents that way. If you save the query, you can also get the same documents in a separate index by using the Reindexer.
Experiments and Tutorial projects¶
Metadiscourse Study Experiment¶
The metadiscourse study corpus is a sample of academic texts split into sentences, annotated with Estonian metadiscourse markers by Bwrite. This corpus is in project 1: Metadiscourse Study. It consists of indices for Estonian (est_metadiscourse_annotations, metadiscourse_annotated, metadiscourse_et_with_facts) and Latvian (metadiscourse_annotated_latvian) annotations.
Bwrite Raw Data Corpora¶
These are projects 3, 4 and 5. We separated the raw data by language for easier processing. The raw data corpora contains the first variant of the corpora as well as some documents that were too long (probably whole journal issues). There are also indices for fixing problems that went wrong while processing the original data.
Marleen’s Master Thesis Project¶
Project 6: Marleeni MA contained indices related to Marleen’s MA, now it only contains two regex taggers she used for finding documents for her MA.
Sentiment Experiments¶
This is project 9: Sentiment study. The sentiment experiments include Estonian indices used for lexicon- or LLM-based sentiment analysis.
Index name |
Description |
|---|---|
senti_test_et_2 |
20 test documents split into sentences |
senti_test_et2_split_pos |
20 test documents split into sentences with sentiment words from lexicons as facts |
sentiment_experiment_ling2 |
200 test documents used for the LLM-based sentiment analysis (as full documents) |
ery_docs |
Additional 30 documents added to the LLM experiment later on (full documents) |
et_llm_sentiment_test_wl |
20 test documents with wordlists and LLM sentiment (as sentences) |
et_llm_sentiment_test_2_2 |
200 test documents with LLM and wordlist sentiment (as paragraphs) |
et_llm_sentiment_test_2_ery2 |
Additional 30 test documents with LLM and wordlist sentiment (as paragraphs) |
et_llm_sentiment_test_final |
et_llm_sentiment_test_2_2 and et_llm_sentiment_test_2_ery2 together (as paragraphs) |
et_llm_sentiment_test_2_2_3_23 / et_llm_sentiment_test_2_2_5_19 |
Annotation indices for the 200 test documents (only positive and negative) |
et_llm_sentiment_test_2_ery2_3_25 / et_llm_sentiment_test_2_ery2_5_25 |
Annotation indices for the additional 30 documents (only positive and negative) |
Demo project¶
This is project 10. A tutorial project used for building this manual and meant for practicing Texta Toolkit features.
Index name |
Corpus language |
Description |
|---|---|---|
estonian_documents_20 |
Estonian |
20 random Estonian documents |
estonian_sentences_20 |
Estonian |
20 random Estonian documents as sentences, has extra metadata like Discipline and sentiment words |
latvian_documents_20 |
Latvian |
20 random Latvian documents |
latvian_sentences_20 |
Latvian |
20 random Latvian documents as sentences |
lithuanian_documents_20 |
Lithuanian |
20 random Lithuanian documents |
lithuanian_sentences_20 |
Lithuanian |
20 random Lithuanian documents as sentences |
estonian_20_ba_ma |
Estonian |
sentences from BA and MA theses (from estonian_sentences_20) |
ba_ma_custom_1 / ba_ma_custom_2 |
Estonian |
sentences from BA and MA theses (from estonian_sentences_20) split custom |
ba_ma_soc_hum_1 / ba_ma_soc_hum_2 |
Estonian |
sentences from BA and MA theses (from estonian_sentences_20) split equal |
ba_ma_soc_hum_org1 / ba_ma_soc_hum_org2 |
Estonian |
sentences from BA and MA theses (from estonian_sentences_20) split original |
estonian_20_ba_ma_3_21 |
Estonian |
sentences from BA and MA theses (annotation index) |
Metadata (Discipline) project¶
This is project 12. It was used to apply discipline metadata to the final indices. It contains a few queries for checking if the Discipline metadata is added to documents.