For Advanced Users¶
Authentication¶
Create an account. You can also go to http://bwrite.texta.ee/api/v2/rest-auth/registration/ to register.
Go to http://bwrite.texta.ee/api/v2/rest-auth/login/ to get an API key. You can use it for browsing the API, and this is also the token you’ll be using for running scripts via API.
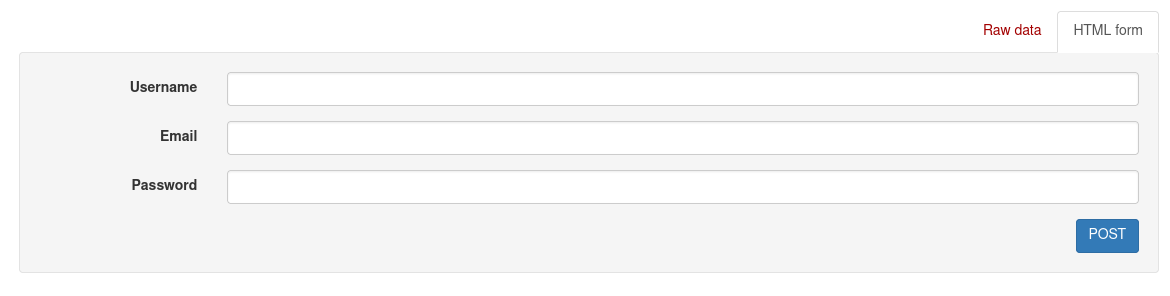
Enter your username, email address and password, then press POST to get the API token.
User Access and Index Management¶
User Access and Index Management can be accessed in the toolkit by superusers at http://bwrite.texta.ee/#/management/users. You can also access it by clicking on the Management option after clicking your username.
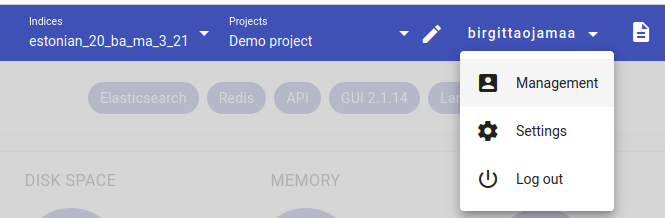
Superusers can access all the functionalities described in this manual and share those privileges with others.
Superusers can also delete other users, delete indices and remove stuck tasks.

An example of the users management page.
Manage user rights (if user is superuser or not) and add users to projects using the Users tab. You can also delete user accounts here.

An example of the indices management page.
Delete indices under the Actions in Indices tab.
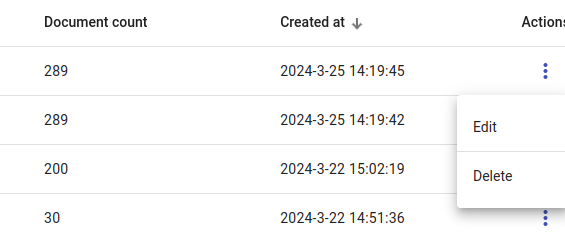
You can also add descriptions under Edit and sort by index ID, name, size or date created.

Remove stuck tasks in the Celery Tasks tab by pressing on the Purge Tasks button.
Note
Purging tasks will cancel any tasks in progress!
Health¶
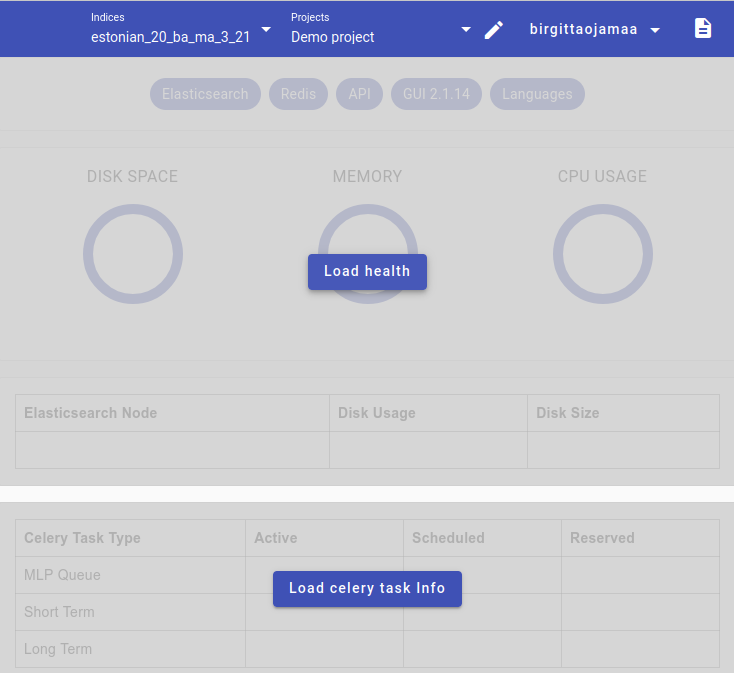
Access Health by going into Project view and pressing the button Load Health on the right. You can also load Celery task info*.
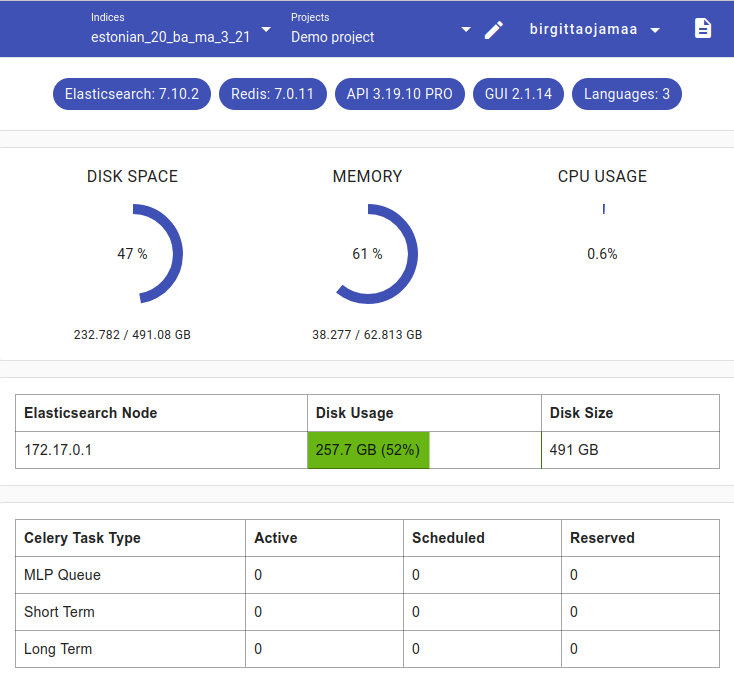
Health shows how much disk space, memory and CPU is currently used on all projects.
If the disk space or memory gets very full, some indices or tasks should be deleted.
Creating a New Index via API¶
Note
All API scripts are presented in Python.
Imports:
import csv
import requests
import elasticsearch
import elasticsearch_dsl
import json
import os
import regex as re
import warnings
import urllib3
warnings.simplefilter('ignore', urllib3.exceptions.SubjectAltNameWarning)
warnings.simplefilter('ignore', urllib3.exceptions.InsecureRequestWarning)
Setting up the API and index values:
bwrite_url = "http://bwrite.texta.ee/api/v1"
bwrite_index = "clean_documents_lt_v2"
new_index_name = "clean_2_add_year_lt"
bwrite_token = "Token X"
bwrite_header = {'Authorization': bwrite_token}
bwrite_project_id = 5
Add the bwrite_index value if you are intending to scroll an index as well, this is the name of the index you’ll be scrolling.
new_index_name will be the name of the newly created index.
For bwrite_token, replace X with the token from Authentication.
Replace the bwrite_project_id to refer to the correct project.
Creating a new index:
import os
res = requests.post(os.path.join(bwrite_url, "index/"), verify=False, headers=bwrite_header, data={"is_open": True, "name": new_index_name})
#get id of newly created index
res = requests.get(os.path.join(bwrite_url, "index/"), verify=False, headers=bwrite_header)
indices = res.json()
for index in indices:
if(index["name"] == new_index_name):
new_index_id = index["id"]
break
#add mapping to the index
res = requests.post(os.path.join(bwrite_url, "index", str(new_index_id), "add_facts_mapping/"), headers=bwrite_header, verify=False)
After creating a new index, add it manually to the correct project.
Scrolling an Index via API¶
Imports:
import csv
import requests
import elasticsearch
import elasticsearch_dsl
import json
import os
import regex as re
import warnings
import urllib3
warnings.simplefilter('ignore', urllib3.exceptions.SubjectAltNameWarning)
warnings.simplefilter('ignore', urllib3.exceptions.InsecureRequestWarning)
Setting up the API and index values:
bwrite_url = "http://bwrite.texta.ee/api/v1"
bwrite_index = "clean_documents_lt_v2"
bwrite_token = "Token X"
bwrite_header = {'Authorization': bwrite_token}
bwrite_project_id = 5
Add the bwrite_index value if you are intending to scroll an index as well, this is the name of the index you’ll be scrolling.
For bwrite_token, replace X with the token from Authentication.
Replace the bwrite_project_id to refer to the correct project.
Endpoints and payload to scroll the data:
#endpoint to scroll the data
scroll_url = bwrite_url + "/projects/" + str(bwrite_project_id) + "/scroll/"
#endpoint for document importer
importer_url = bwrite_url + "/projects/" + str(bwrite_project_id) + "/document_importer/"
#payload for scroll endpoint
data = {
"indices": [bwrite_index],
"with_meta": True,
"documents_size": 100
}
If you have errors while scrolling, you are encouraged to make the chunk size smaller. So in the data section, you alter the variable documents_size to be smaller than 100, for example 50 or 10.
Scrolling:
#use this initially to get scroll id
res = requests.post(scroll_url, headers=bwrite_header, json=data, verify=False).json()
#update payload with scroll id
data["scroll_id"] = res["scroll_id"]
times_scrolled = 1
while True:
docs_count = len(res["documents"])
#break if scroll is empty
if(docs_count == 0):
break
print(str(times_scrolled),"processing", docs_count, "docs;")
new_docs = list()
for doc in res["documents"]:
pass
#retrieve next batch from scroll
res = requests.post(scroll_url, headers=bwrite_header, json=data, verify=False).json()
times_scrolled += 1
In the for-loop, add a function for what you wish to do with the documents you are scrolling instead of the pass command, whether you want to save the files on disk, view information or something else.
Scrolling an Index into a New Index¶
Start with Creating a New Index via API.
Endpoints and payload to scroll the data:
#endpoint to scroll the data
scroll_url = bwrite_url + "/projects/" + str(bwrite_project_id) + "/scroll/"
#endpoint for document importer
importer_url = bwrite_url + "/projects/" + str(bwrite_project_id) + "/document_importer/"
#payload for scroll endpoint
data = {
"indices": [bwrite_index],
"with_meta": True,
"documents_size": 100
}
If you have errors while scrolling, you are encouraged to make the chunk size smaller. So in the data section, you alter the variable documents_size to be smaller than 100, for example 50 or 10.
Scrolling:
#use this initially to get scroll id
res = requests.post(scroll_url, headers=bwrite_header, json=data, verify=False).json()
#update payload with scroll id
data["scroll_id"] = res["scroll_id"]
times_scrolled = 1
while True:
docs_count = len(res["documents"])
#break if scroll is empty
if(docs_count == 0):
break
print(str(times_scrolled),"processing", docs_count, "docs;")
new_docs = list()
for doc in res["documents"]:
pass
new_docs.append({"_index": new_index_name, "_doc": new_index_name, "_source": doc["_source"]})
#use doc's id to construct endpoint for patch request and send updated document as payload
import_res = requests.post(importer_url, headers=bwrite_header, json={"documents": new_docs, "split_text_in_fields": []}, verify=False)
if import_res.ok == False:
print(import_res.text)
new_docs = list()
#retrieve next batch from scroll
res = requests.post(scroll_url, headers=bwrite_header, json=data, verify=False).json()
times_scrolled += 1
In the for-loop, add a function for what you wish to do with the documents you are scrolling instead of the pass command, whether you want to apply a new fact to the document, use a regular expression or something else. The modified document will then be added to the new index.
Fact Structure¶
Example fact structure:
new_fact = {
"spans": json.dumps([[0,0]]),
"str_val": <fact_value as a string>,
"sent_index": <sentence index as integer, 0 if text is not made into sentences>,
"fact": <fact_name as a string>,
"doc_path": <path to field, for example "text" or "text_mlp.lemmas">
}
For spans, if you have found correct spans, then put the span values in json.dumps, for example json.dumps([[5,15]])
Fact structure is important to follow, otherwise facts will not display correctly.
Script Examples¶
Regexes¶
Publication year regex:
year_pattern = r"(?<!\d)(19[0-9][0-9]|20[01][0-9]|20[2][0-3])(?!\d)"
Regex for citations:
only_numbers_regex = r"[0-9]+"
year_regex = r"(1[0-9]{3}|20[0-2][0-9])(\p{Ll})?"
block_year_regex = r"[(\[]?(1[0-9]{3}|20[0-2][0-9])(\p{Ll})?[)\]]?"
names_regex = r"([0-9]*\. )?\p{Lu}\p{Ll}{1,}(-\p{Lu}\p{Ll}{1,})?(,?\p{Lu}\.)*[^\n\d]* [(\[]?(1[0-9]{3}|20[0-2][0-9])(\p{Ll})?[)\]]?(?!-)"
one_name_regex = r"\p{Lu}[\p{Ll}\p{Lu}]{1,}(-\n?\p{Lu}[\p{Ll}\p{Lu}]{1,})?"
one_or_more_names_regex = one_name_regex + r"((\,[ \n]|[ \n]ja[ \n]|[ \n]un[ \n]|[ \n]ir[ \n]|[ \n]&[ \n])" + one_name_regex + r")*" +r",?[ \n](1[0-9]{3}|20[0-2][0-9])(\p{Ll})?" + r"(;[ \n]" + one_name_regex + r"((\,[ \n]|[ \n]ja[ \n]|[ \n]un[ \n]|[ \n]ir[ \n]|[ \n]&[ \n])" + one_name_regex + r")*" + r"([ \n]et al|[ \n]jt|[ \n]ir kt|[ \n]un citi)" +r",?[ \n](1[0-9]{3}|20[0-2][0-9])(\p{Ll})?)?"
#Estonian keywords
ET_cite = r"(Kasutatud kirjandus|KASUTATUD KIRJANDUS|Kasutatud allikad|KASUTATUD ALLIKAD|Allikad|ALLIKAD|VIITED|Viited)"
ET_appendix = r"(LISAD|Lisad)"
#Latvian keywords
LV_cite = r"(Bibliogrāfija|LITERATŪRA|IZMANTOTĀS LITERATŪRAS UN AVOTU SARAKSTS|IZMANTOTO AVOTU UN LITERATŪRAS SARAKSTS|AVOTU UN LITERATŪRAS SARAKSTS|IZMANTOTĀS LITERATŪRAS SARAKSTS|IZMANTOTĀ LITERATŪRA|Vēres|LITERATŪRAS SARAKSTS)"
LV_appendix =r"(Pielikumu saraksts|Pielikumi|ANNOTATION|PIELIKUMI|RÉSUMÉ|SUMMARY|Publikācijas, ziņojumi kongresos un konferencēs par pētījuma tēmu|PIELIKUMS)"
#Lithuanian keywords
LT_cite = r"(LITERATŪROS IR KITŲ INFORMACIJOS ŠALTINIŲ SĄRAŠAS|LITERATŪROS SĄRAŠAS|Literatūros sąrašas|LITERATŪRA|INFORMACIJOS ŠALTINIŲ SĄRAŠAS|INFORMACINIAI ŠALTINIAI|NAUDOTA LITERATŪRA|LITERATŪROS ŠALTINIAI)"
LT_appendix = r"(PRIEDAI|Priedai|Priedų sąrašas|AUTORĖS PASKELBTI DARBAI|GRAFINĖ DALIS|DARBO APROBACIJA IR PUBLIKACIJOS|Summary|PUBLIKACIJŲ SĄRAŠAS DISERTACIJOS TEMA)"
Title pages regex:
title_page_et = [r"(?s)Mina,?(\n|w*|.*| )*,?[ \n]tõendan", "Olen koostanud", r"\n(- )?(2|3|4|5)( -)?\n", "[Ss]ummary", "SUMMARY", "[Kk]okkuvõte", "KOKKUVÕTE", "[Ll]ühikokkuvõte" "LÜHIKOKKUVÕTE", r"[Aa]utori ?deklaratsioon", "AUTORIDEKLARATSIOON", "SISUKORD", r"[Ss]isukord", "Resümee", "Abstract"]
title_page_lv = [r"\n(- )?(2|3|4|5)( -)?\n", "ANOTĀCIJA", r"[aA]notācija", "SATURS", "IEVADS", "SATURA RĀDĪTĀJS", r"[Ss]aturs", r"[iI]evads", "PRIEKŠVĀRDS", r"[aA]bstract"]
title_page_lt = [r"\n(- )?(2|3|4|5)( -)?\n", r"[sS]ummary", "SUMMARY", r"[rR]eziumė", "TURINYS", r"[tT]urinys" r"[Įį]vadas", r"[aA]bstract"]
Functions¶
Removing citations and appendices from Estonian University works:
#Estonian searchwords
ET_cite = r"(\bKasutatud kirjandus\b|\bKASUTATUD KIRJANDUS\b|\bKasutatud allikad\b|\bKASUTATUD ALLIKAD\b|\bAllikad\b|\bALLIKAD\b|\bVIITED\b|\bViited\b|\bKIRJANDUS\b|\bKirjandus\b)"
#added "Kirjandus/KIRJANDUS" to the citation regex pattern
#processing one document, input is document text, lemmas, pos_tags.
def process_one_doc(doc_text, lemmas, pos_tags):
start_span = (len(doc_text), 0)
#trying to find the start and end of the reference block
#we assume that everything after this block is also not relevant (appendices etc).
d = re.finditer(ET_cite, doc_text)
if d:
cite_matches = [match.span() for match in d]
start_span = cite_matches[-1]
text_wo_cite = doc_text[0:start_span[0]] #splitting rest of text
ref_tokens = doc_text[start_span[1]:len(doc_text)]
lemmas_wo_cite = " ".join(lemmas.split(" ")[0:-len(ref_tokens.split(" "))])
pos_wo_cite = " ".join(pos_tags.split(" ")[0:-len(ref_tokens.split(" "))])
return text_wo_cite, lemmas_wo_cite, pos_wo_cite
Paragraphs segmentation functions:
#chunking longer text into chunks of 2000
def chunks(iterable, size=2000):
iterator = iter(iterable)
for first in iterator:
yield itertools.chain([first], itertools.islice(iterator, size - 1))
def split_paragraphs(paragraph):
para_chunks = chunks(paragraph, size=2000)
para_chunks = [" ".join(chunk) for chunk in para_chunks]
return para_chunks
#splitting using the newline (paragraph/line end)
def split_on_newline(paragraph):
newlines = paragraph.split("\n")
over_length = [newline for newline in newlines if not check_length(newline.split(" "))]
if over_length:
not_over_length = [newline for newline in newlines if check_length(newline.split(" "))]
for o_l in over_length:
new_chunks = split_paragraphs(o_l.split(" "))
not_over_length.extend(new_chunks)
return not_over_length
else:
return newlines
def check_length(t_paragraph):
if len(t_paragraph) < 2000: #we check that a segment has under 2000 tokens
return True
else:
return False
def check_paras_length(paras):
final_paras = []
for para in paras:
if " " in para:
tokenized_para = para.split(" ")
if not check_length(tokenized_para):
if "\n" in para: #if newlines are in a long paragraph, we split on newlines
para_chunks = split_on_newline(para)
final_paras.extend(para_chunks)
else: #otherwise make into 2000 token chunks
para_chunks = split_paragraphs(tokenized_para)
final_paras.extend(para_chunks)
else:
final_paras.append(" ".join(tokenized_para))
else:
final_paras.append(para)
return final_paras
#adding it all together
def segment_to_paragraphs(doc_text):
re_pattern = '(?<=[.?!"]( )?\n)'
paras = re.split(re_pattern, doc_text)
final_paras = check_paras_length(paras)
nozero_paras = [para for para in final_paras if len(para) > 1]
return nozero_paras
Applying wordlists:
#table of pos_tags
NOUNS = ["n", "NOUN", "S", "S/S", "A/S"]
VERBS = ["v", "VERB", "V", "V/V", "D/V"]
ADVERBS = ["r", "ADV", "D", "A/D", "D/V"]
ADJECTIVES = ["a", "ADJ", "A", "A/S", "A/D"]
INTERJECTION = ["Interj.", "INTJ"]
#list of the dictionaries and their names
lex_dicts = [senti_pos, senti_neg, eki_pos_dict3, eki_neg_dict3, est_pos2, est_neg2]
lex_dict_names = ["senti_pos", "senti_neg", "eki_pos_dict3", "eki_neg_dict3", "est_pos2", "est_neg2"]
def add_facts(val, label, span_start, span_end, path): #adding facts
new_fact = {"spans": json.dumps([[span_start,span_end]]), #make spans into acceptable spans
"str_val": val,
"sent_index": 0,
"fact": label,
"doc_path": path,
}
return new_fact
#comparing part of speech tags
def compare_pos(lemma_pos_tag, lex_pos_tag):
if (lemma_pos_tag in NOUNS) and (lex_pos_tag in NOUNS):
return True
elif (lemma_pos_tag in VERBS) and (lex_pos_tag in VERBS):
return True
elif (lemma_pos_tag in ADVERBS) and (lex_pos_tag in ADVERBS):
return True
elif (lemma_pos_tag in ADJECTIVES) and (lex_pos_tag in ADJECTIVES):
return True
elif (lemma_pos_tag in INTERJECTION) and (lex_pos_tag in INTERJECTION):
return True
return False
#searching for negation words that negate a found item
counter_slop_words = ["ei", "mitte", "ära"]
counter_slop = 1
def get_slop_lemmas_before_and_after(counter_slop, counter_slop_words, lemmas_txt, lemma_start, lemma_end):
before = lemmas_txt[:lemma_start].split()
after = lemmas_txt[lemma_end:].split()
counter_slop = counter_slop +1
before_sl = before[-counter_slop:]
after_sl = after[:counter_slop]
#print(before_sl, after_sl)
if len(set(counter_slop_words).intersection(set(before_sl))) != 0:
return True
if len(set(counter_slop_words).intersection(set(after_sl))) != 0:
return True
else:
return False
#chunking the files for easier processing
n = 100
# using list comprehension for chunking
processed_files_chunk = [processed_files[i * n:(i + 1) * n] for i in range((len(processed_files) + n - 1) // n )]
for chunk in processed_files_chunk:
new_docs = []
for item in chunk:
text = item["para"]
doc = {"_source":{}}
doc["_source"]["text_mlp"] = item[mlp_text]["text_mlp"]
doc["_source"]["text_paragraph"] = text
doc["_source"]["texta_facts"] = item["texta_facts"]
doc["_source"]["meta"] = {"file": item["doc_id"]}
facts = doc["_source"]["texta_facts"]
facts.append(add_facts(item["LLM sentiment"], "LLM_sentiment", 0, 0, "text_paragraph")) #if you already have processed the files with LLM
lemmas_txt = doc["_source"]["text_mlp"]["lemmas"]
lemmas = doc["_source"]["text_mlp"]["lemmas"].split() #splitting the lemmas into tokens
postags = doc["_source"]["text_mlp"]["pos_tags"].split() #splitting the pos tags into tokens
for i, lemma in enumerate(lemmas):
facts_vals = [fact["str_val"] for fact in facts] #getting all the fact values
if lemma not in facts_vals: #checking to see that we haven't already analyzed the lemma
for lex_dict in lex_dicts: #go through all the dictionaries
if lemma in lex_dict:
if compare_pos(postags[i], lex_dict[lemma]):
lemma_w_borders = r"\b"+lemma+r"\b" #adding borders on the lemma to avoid finding compound words
all_ones = re.finditer(lemma, lemmas_txt) #finding all the matches of that lemma in the text
for item in all_ones:
if get_slop_lemmas_before_and_after(counter_slop, counter_slop_words, lemmas_txt, item.start(), item.end()) == False:
facts.append(add_facts(lemma, lex_dict_names[lex_dicts.index(lex_dict)], item.start(), item.end(), "text_mlp.lemmas"))
doc["_source"]["texta_facts"] = facts
new_docs.append({"_index": new_index_name, "_doc": new_index_name, "_source": doc["_source"]})
OpenAI completions prompt and call:
from openai import OpenAI
client = OpenAI(api_key="XXX") #insert OpenAI API key
prompt_instruction = """You are an assistant that classifies academic texts as positive, neutral or negative based on sentiment analysis.
Consider that the domain is academic texts, so lexicon-based sentiment analysis might not be accurate.
The user inputs in Estonian, Latvian or Lithuanian. You must answer in English with the one-word sentiment label.
"""
def put_completions(user_message):
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": prompt_instruction},
{"role": "user", "content": user_message}
]
)
return((completion.choices[0].message))
Note
When using the OpenAI sentiment prompt, consider adding in a sentence about what to do if the input is in another language (for example, respond “Neutral” in that case).
Labeling segmented files using GPT-4:
def process_files(pre_files):
with open("segmented_files_processed_temp2.jl", 'a', encoding='utf-8') as fout:
for item in pre_files:
paras = item["text_paras"]
for para in paras:
new_item = {}
new_item["para"]=para
new_item["doc_id"]=item["doc_id"]
new_item["texta_facts"] = item["texta_facts"]
if re.search(r"[\p{Ll}\p{Lu}]{2,}", para):
get_answer = put_completions(para).content
if type(get_answer) == str:
new_item["LLM sentiment"] = get_answer
json.dump(new_item, fout)
fout.write("\n")
else:
new_item["LLM sentiment"] = get_answer
print(new_item)
else:
new_item["LLM sentiment"] = "Neutral"
json.dump(new_item, fout)
fout.write("\n")
Evaluating LLM and wordlist results for documents:
def consolidate_wordlists(facts): #consolidating wordlist sentiment for each paragraph
EKI_labels = []
est_labels = []
for fact in facts:
EKI_val = "Neutral"
est_val = "Neutral"
if len(fact) > 1:
eki_pos = 0
eki_neg = 0
est_pos = 0
est_neg = 0
for subfact in fact:
if "eki" in subfact["fact"]:
if "neg" in subfact["fact"]:
eki_neg += 1
if "pos" in subfact["fact"]:
eki_pos += 1
elif "est" in subfact["fact"]:
if "neg" in subfact["fact"]:
est_neg += 1
if "pos" in subfact["fact"]:
est_pos += 1
if eki_neg > eki_pos:
EKI_val = "Negative"
elif eki_pos > eki_neg:
EKI_val = "Positive"
elif est_neg > est_pos:
est_val = "Negative"
elif est_pos > est_neg:
est_val = "Positive"
EKI_labels.append(EKI_val)
est_labels.append(est_val)
return EKI_labels, est_labels
def test_uni(para_facts): #if "University" is in facts, then the doc is thesis
uni_search = [x for x in para_facts if x["fact"]=="University"]
if uni_search:
return True
else:
return False
doc_scores = []
for doc, facts in doc_id_and_facts.items(): #getting the facts by doc
final_row = {"doc_id": doc}
uni_yes = test_uni(facts[0])
final_row["is_BA"] = uni_yes
LLM_vals = []
for para in facts:
para_LLM_vals = list(set([x["str_val"] for x in para if x["fact"]=="LLM_sentiment"]))
LLM_vals.append(para_LLM_vals[0])
final_row["total_paragraphs"] = len(LLM_vals)
EKI_vals, est_vals = consolidate_wordlists(facts)
VALS_set = LLM_vals, EKI_vals, est_vals
VALS_set_names = "LLM_vals", "EKI_vals", "est_vals"
for i, val_set in enumerate(VALS_set):
neg_scores, pos_scores, neu_scores = eval_facts(val_set)
final_row[f"{VALS_set_names[i]}_neg_scores"] = neg_scores
final_row[f"{VALS_set_names[i]}_pos_scores"] = pos_scores
final_row[f"{VALS_set_names[i]}_neu_scores"] = neu_scores
doc_scores.append(final_row)
def write_csv(fn, o_data): #write output into csv
header = ['doc_id', 'is_BA', 'total_paragraphs', 'LLM_vals_neg_scores', 'LLM_vals_pos_scores', 'LLM_vals_neu_scores', 'EKI_vals_neg_scores', 'EKI_vals_pos_scores', 'EKI_vals_neu_scores', 'est_vals_neg_scores', 'est_vals_pos_scores', 'est_vals_neu_scores']
with open(fn, 'w') as file:
writer = csv.DictWriter(file, fieldnames=header)
writer.writeheader()
writer.writerows(o_data)
write_csv("sentiment_test27-02-24.csv", doc_scores)
Getting random paragraphs for manual sentiment analysis:
def extract_LLM_sentiment(facts): #extracting LLM sentiment
llm_sentiment = [fact["str_val"] for fact in facts if fact["fact"] == "LLM_sentiment"][0]
return llm_sentiment
def transform_facts(facts): #extracting facts
transformed_facts = {}
sentiment_facts = ["LLM_sentiment", "eki_pos_dict3", "eki_neg_dict3", "est_pos2", "est_neg2"]
fact_keys = [fact["fact"] for fact in facts if fact["fact"] not in sentiment_facts]
for key in fact_keys:
transformed_facts[key]=[fact["str_val"] for fact in facts if fact["fact"]==key][0]
return transformed_facts
def restructure_paras(paras): #restructuring paragraphs and filtering out ones that don't have at least three words
#paragraph structure should be:
#doc_id: {"contents":[{"para":x, "sentiment":y}, {...}], "facts":{x, y, z}}
doc_paras_facts = {}
for item in paras:
para = item["para"]
doc_id = item["doc_id"]
llm_sentiment = extract_LLM_sentiment(item["texta_facts"])
facts = transform_facts(item["texta_facts"])
three_words = re.compile(r"\b[\p{Ll}\p{Lu}]{2,}\b \b[\p{Ll}\p{Lu}]{2,}\b \b[\p{Ll}\p{Lu}]{2,}\b")
if three_words.search(item["para"]):
if doc_id in doc_paras_facts:
doc_paras_facts[doc_id]["contents"].append({"para":para.strip(), "LLM sentiment":llm_sentiment})
else:
doc_paras_facts[doc_id] ={"contents":[{"para":para, "LLM sentiment":llm_sentiment}], "facts":facts}
return doc_paras_facts
def get_rand_int(len_list): #random number generator
rand_int = random.randint(0,len_list)
return rand_int
def get_paras(paras, n):
rand_ints = []
for i in range(0,n):
rand_int = get_rand_int(len(paras)-1)
if rand_int not in rand_ints:
rand_ints.append(rand_int)
else:
rand_int = get_rand_int(len(paras)-1)
rand_ints.append(rand_int)
selected_para = [paras[r_int] for r_int in rand_ints][0]
return selected_para
randparas = []
neg_counter = 0
pos_counter = 0
for doc, vals in re_doc_para.items(): #select semi-random paragraph from each document (we want to get positive/negative and neutral to be pretty balanced)
write_para = {"doc_id":doc, "facts":vals["facts"]}
neg_paras = [item for item in vals["contents"] if item["LLM sentiment"] == "Negative"]
pos_paras = [item for item in vals["contents"] if item["LLM sentiment"] == "Positive"]
neut_paras = [item for item in vals["contents"] if item["LLM sentiment"] == "Neutral"]
if neg_paras:
if neg_counter <= 66:
randpara = get_paras(neg_paras, 1)
write_para.update(randpara)
randparas.append(write_para)
neg_counter += 1
continue
elif pos_paras:
if pos_counter <= 66:
randpara = get_paras(pos_paras, 1)
write_para.update(randpara)
randparas.append(write_para)
pos_counter += 1
continue
else:
randpara = get_paras(neut_paras, 1)
write_para.update(randpara)
randparas.append(write_para)
continue
else:
randpara = get_paras(neut_paras, 1)
write_para.update(randpara)
randparas.append(write_para)
continue
elif pos_paras:
if pos_counter <= 66:
randpara = get_paras(pos_paras, 1)
write_para.update(randpara)
randparas.append(write_para)
pos_counter += 1
continue
else:
randpara = get_paras(neut_paras, 1)
write_para.update(randpara)
randparas.append(write_para)
continue
else:
randpara = get_paras(neut_paras, 1)
write_para.update(randpara)
randparas.append(write_para)
def write_csv(fn, o_data): #write output into csv
header = ['doc_id', 'para', 'facts', 'LLM sentiment']
with open(fn, 'w') as file:
writer = csv.DictWriter(file, fieldnames=header)
writer.writeheader()
writer.writerows(o_data)
write_csv("random_paragraphs_1_2.csv", randparas)
Helpful Links¶
Texta Toolkit Documentation: https://docs.texta.ee/index.html
Elasticsearch 7.10 Reference: https://www.elastic.co/guide/en/elasticsearch/reference/7.10/index.html
Elasticsearch regex syntax reference: https://www.elastic.co/guide/en/elasticsearch/reference/7.10/regexp-syntax.html