Data Extraction and Classification¶
Lexicons and Embeddings¶
Lexicons¶
Lexicons hold lists of words used for searching and can also be used to find similar words with the help of Embeddings.
To access lexicons, click on the Lexicons button in the menu.
Besides creating a new lexicon, you have the option to merge lexicons.

To create a lexicon, click on the Create button and enter a description, then click on Create.

Now the lexicon is created, but doesn’t have any words. You can delete the lexicon or edit its name with the Delete/Edit buttons.

Click on the lexicon to see its contents. You can see four large boxes. The most important of these is the upper right box called Positives, you can ignore the others for now.
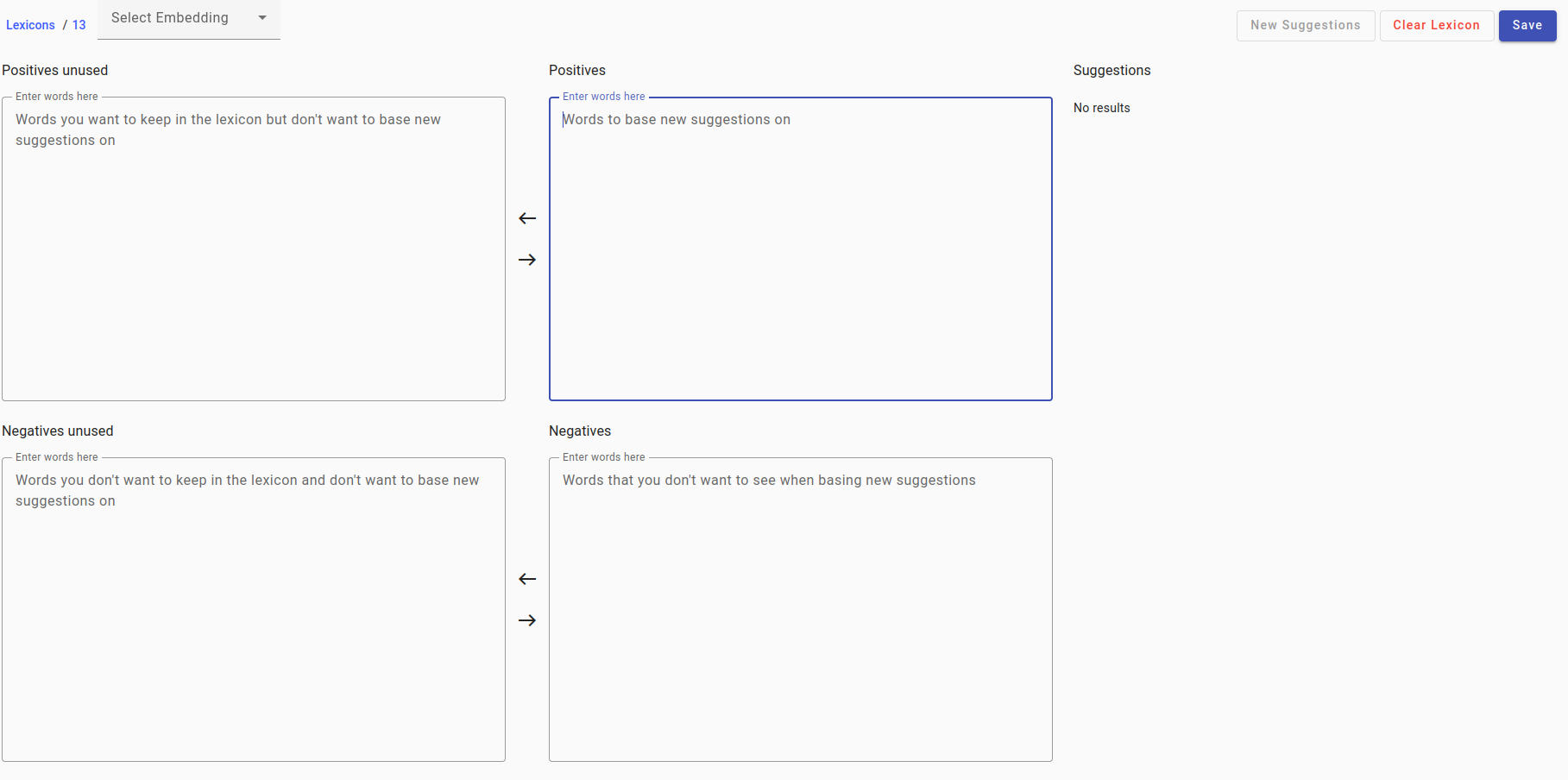
In the upper left you have the option to select an Embedding, on the right you have the buttons Clear Lexicon and Save.
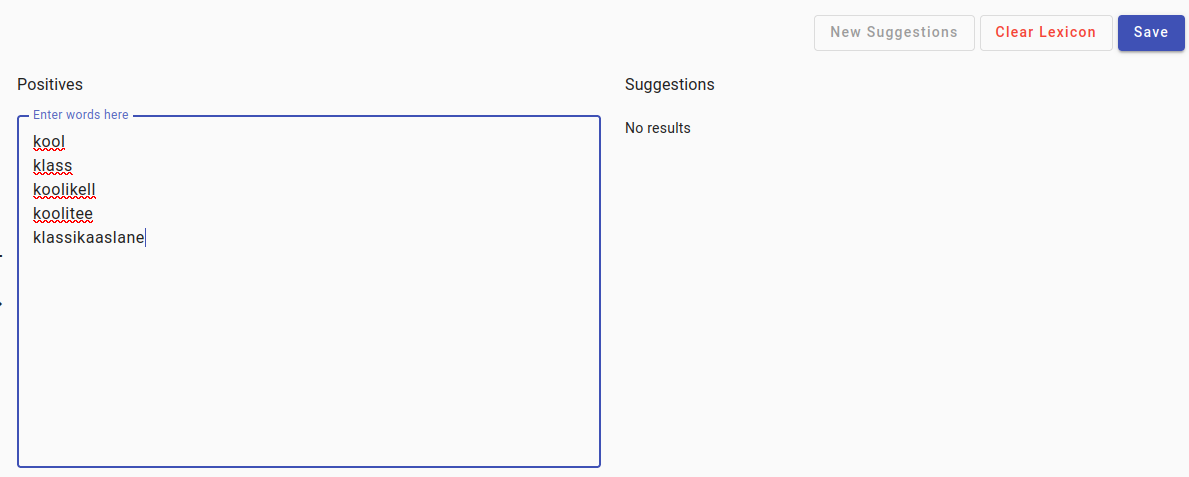
Enter some keywords in the Positives box, then press Save.
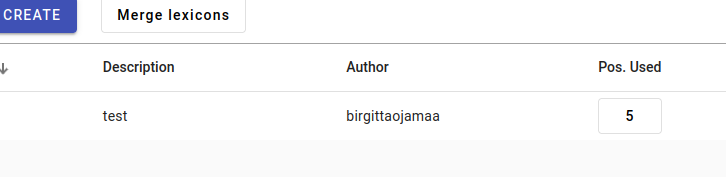
If we go back to the Lexicons page, we can see we have five words in our lexicon now.
Using Lexicons in a Search¶
You can use a lexicon to conduct a search.
Create a lexicon.
After you’ve created a lexicon, go back to the Search view and start an Advanced Search.
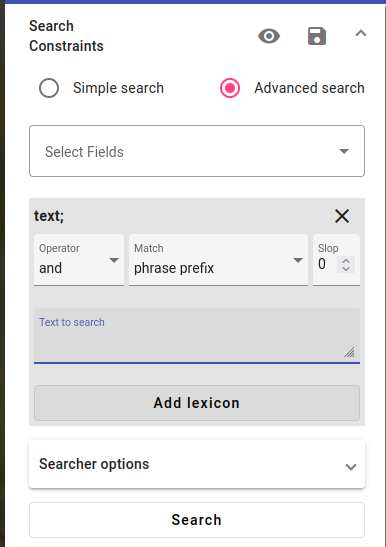
After choosing the text field for the search, we have the option to Add lexicon.
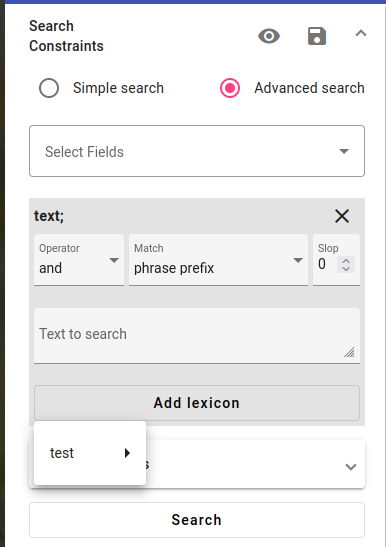
Choose the lexicon and click on it. Hovering over it with the cursor will also show you some of the words in the lexicon.
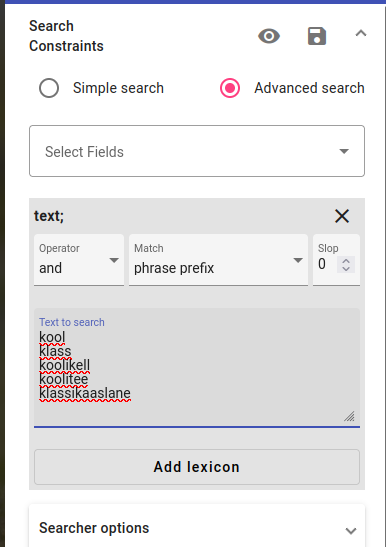
Press Search to search for these words. You can add more words to the search query or change the search constraints without changing the lexicon. You can also change the Operators.
Embeddings¶
Embeddings create a vector representation of a dataset. Embeddings are used for suggesting similar words (for example, to add to your lexicon) and are also used for training some models.
To train an embedding go to the Models menu and select Embeddings, then press Create to create an embedding.
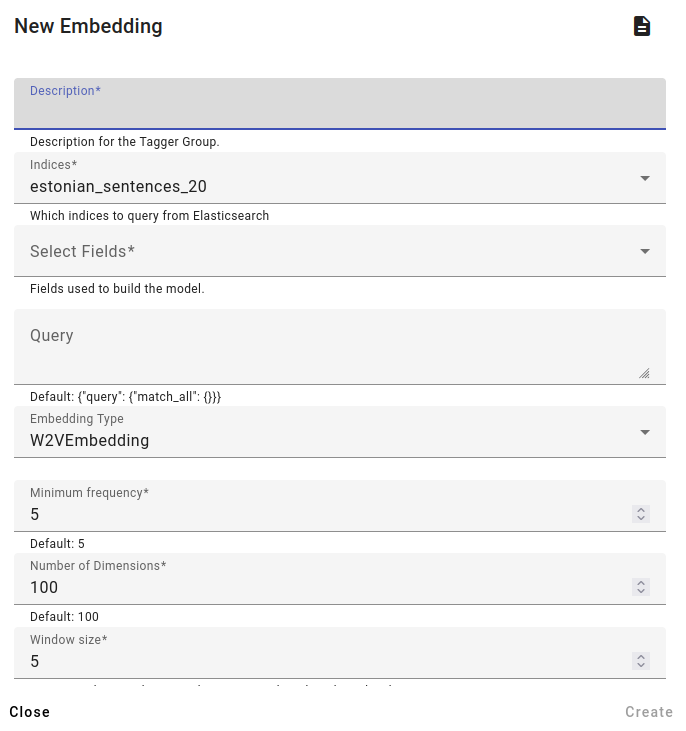
Fill in a description, select indices and fields used to build the model. To get keywords, you should use lemmatized data.
You can also use a query here.
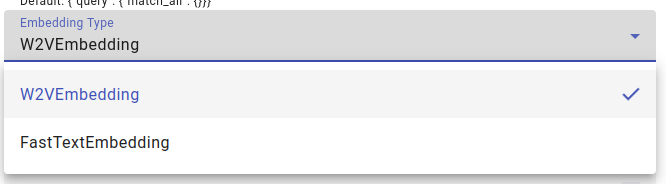
Select the Embedding Type, W2VEmbedding or FastTextEmbedding: Word2vec creates word embeddings based on the entire word, while fastText generates embeddings based on the subword units of a word.
Choose the Minimum Frequency, the minimum amount a word or subword has to appear; Number of Dimensions, more dimensions leads to better results but slower creation; and Context Window Size, the number of words used to determine the context of each word.

Select the number of Epochs, the number of times the corpus will be looked at.
You can also use the phraser, which will chunk up related words into phrases.
Press Create to create the embedding. This will take a little bit of time. You can refresh the page to see the progress.
Using embeddings for generating new words into a lexicon¶
After training an embedding, you can go back to your test lexicon.
Select the test embedding.
Now you can press on the New Suggestions button in the upper right.

The new suggestions will appear on the far right. If you click on a suggestion, it will automatically be added to Positives and used to find more keywords.
You can use the arrows in the middle to exchange the Positives with Positives Unused (will not be used to give new suggestions but will remain in the lexicon) and Negatives with Negatives Unused. The Negatives will also affect the new suggestions.

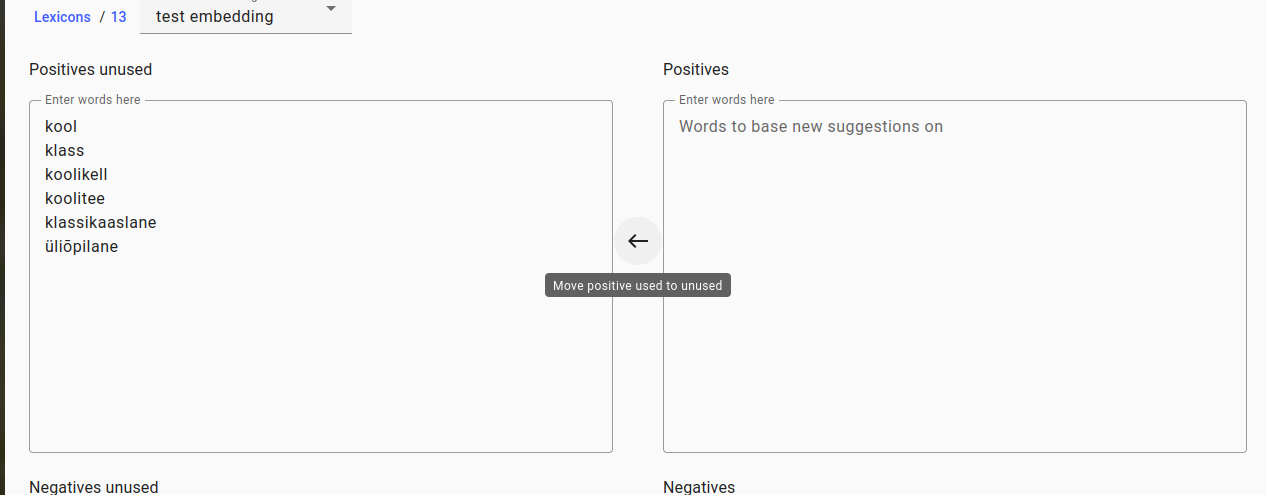
After selecting all the new suggestion words into Positives, you can click on the New Suggestions button again to receive new suggestions. The words that weren’t selected automatically move into the Negatives Unused section.
After you have received all the suggestions you need, click on Save in the upper right to save the lexicon.
Metadata Extraction and Labeling¶
Let’s say you’ve identified something similar about a group of documents, maybe they all contain a certain word or a phrase/list of words in a certain field.
By finding all the documents that contain these similarities, you can generate metadata facts. If there are certain set words or phrases associated with the metadata, then it is easy to find using Search Query Taggers.
In some cases, the keywords are more complicated and require different variants or could have misspellings. In these cases a regular expression makes more sense.
Search Query Taggers¶
Search Query Taggers use search queries as the base for extracting data from a given field.
Make sure you have a query ready.
To access Search Query Taggers, click on Models and select Search Query Taggers. Select Create from the menu.
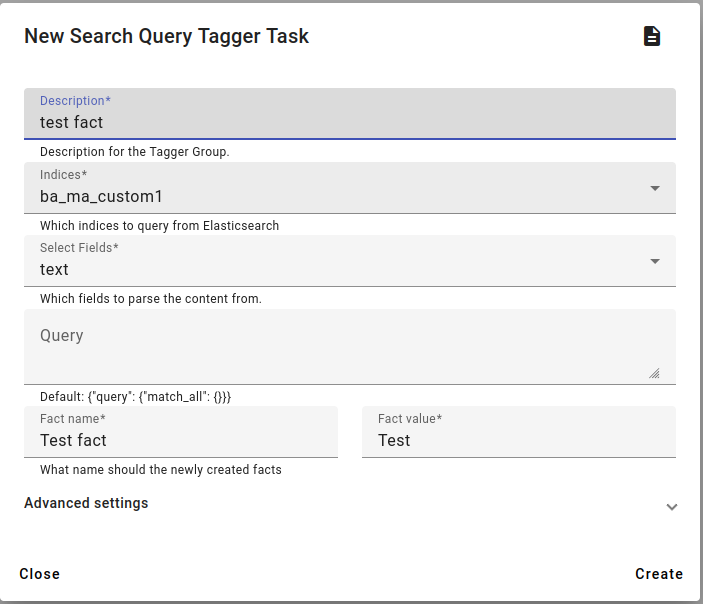
Insert the task description, choose the indices and fields. Consider that the index you choose will obtain a new fact during this process.
Select the saved query for this metadata, for example a query for the name of a university. In this example case, there is no query and the test metadata will be associated with all documents.
Select the Fact name, this should be a general category, like Genre, University, Discipline etc.
Select the Fact value. Examples: genre type like MA Thesis, university name like University of Latvia, discipline type like Social science etc.
Then click Create to create the task.

The result of adding the test fact.
Regex Taggers¶
Regex Taggers are a way to create more complex search queries with regular expressions.
To use Regex Taggers, go to Models and open Regex Taggers.
Press Create to create a new regex tagger or Multitag Text for testing already created regex taggers.
Creating a regex tagger creates the regular expression pattern for finding matching documents and you can use the pattern for testing or apply to whole documents and indices.
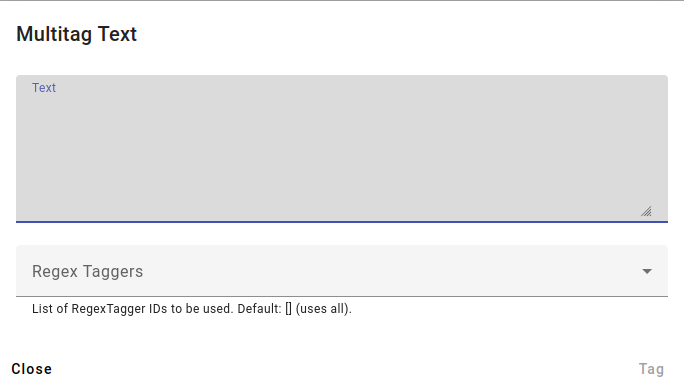
An example of the multitag menu
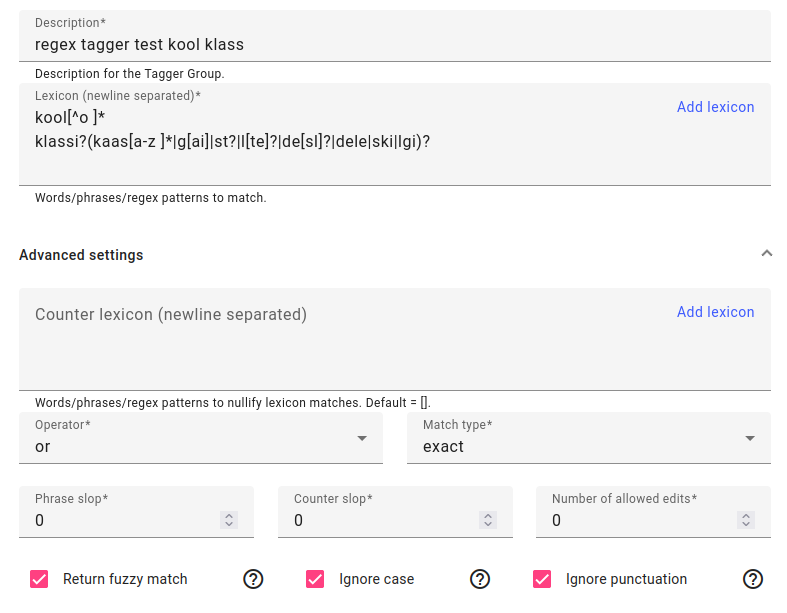
To train a new regex tagger, write in regex tagger description.
In the lexicon field, you can add a lexicon using the Add lexicon button or write in your search terms - you can use Elasticsearch regular expression syntax for these items.
Under advanced settings you can use a counter lexicon (words or phrases that automatically negate the match), choose the operator and the match type, as well as phrase slop (how many words can be between between a phrase), counter lexicon slop (how many words between a counter lexicon item and match item) and number of allowed edits (to account of misspellings).
You can also choose whether to return fuzzy matches, ignore case or to ignore punctuation.
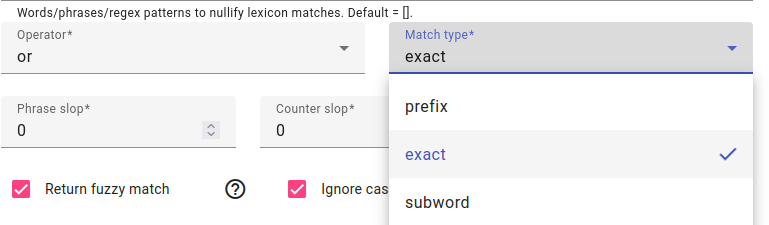
Match type can be prefix, exact or subword.
Exact match matches the exact word
Prefix match allows for suffixes to be added to the word
Subword match can also find the word sequence from inside another word - for example searching for ja using a subword match will also result in matches like kajakas.
Press Create to create the regex tagger.
Now the regular expression pattern is created, you can use it in different ways:
For testing matches, use the Multitag Text button in the menu or go to the task’s Actions and select Tag Text.
You can also Tag Random Doc, Apply to indices, Edit, Duplicate or Clone & Edit and of course Delete the task.
Some Tag text examples:
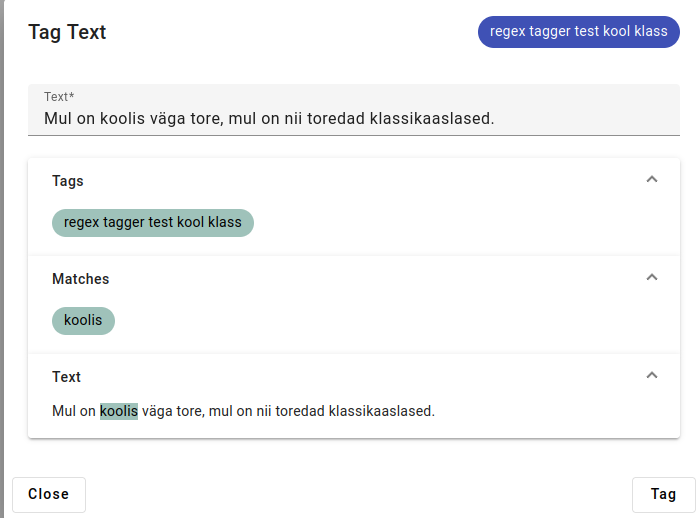
The regex tagger found a match for “koolis”.
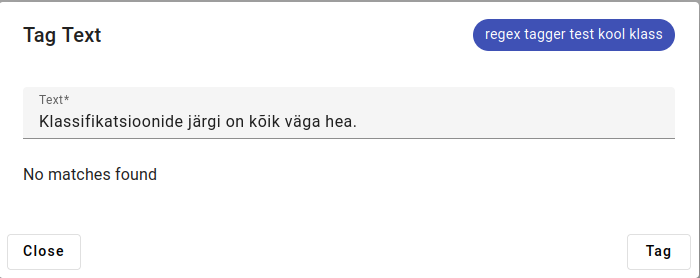
No match found for klassifikatsioonide - the regular expression is to find word that start with “klassi”, but the specifications after that rule out “klassifikatsioonide”.
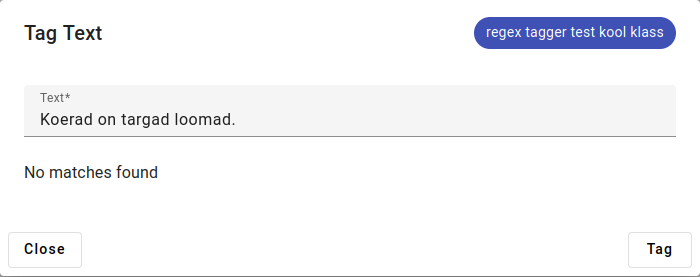
A sentence without any of the regex tagger lexicon present.
When the regex tagger is applied to indices, consider that it will add a new fact to the index.
To apply the regex tagger to indices, select the field the regex pattern will try to match with and optionally, choose the Fact name and Fact value (by default the tagger match) of your new fact.
Adding spans is recommended, since it will allow the Searcher to highlight created facts.
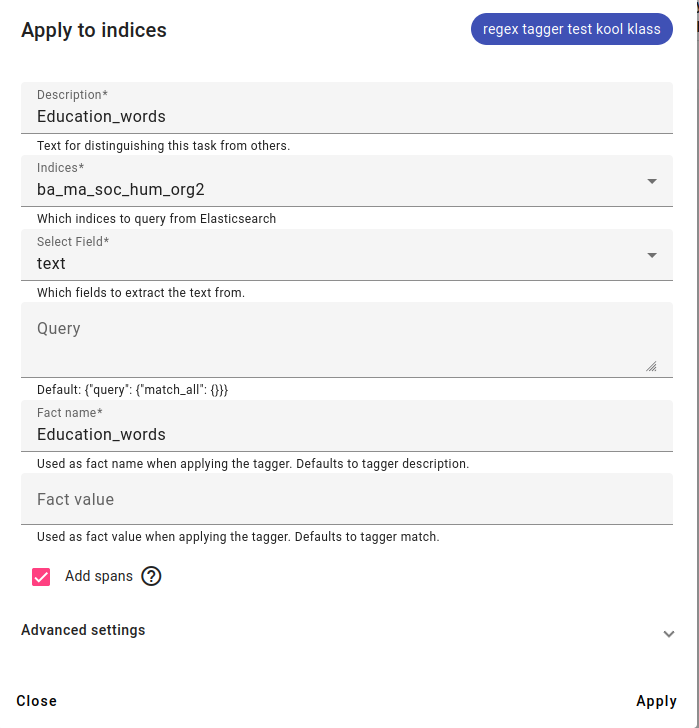
An example using the regex tagger trained before.
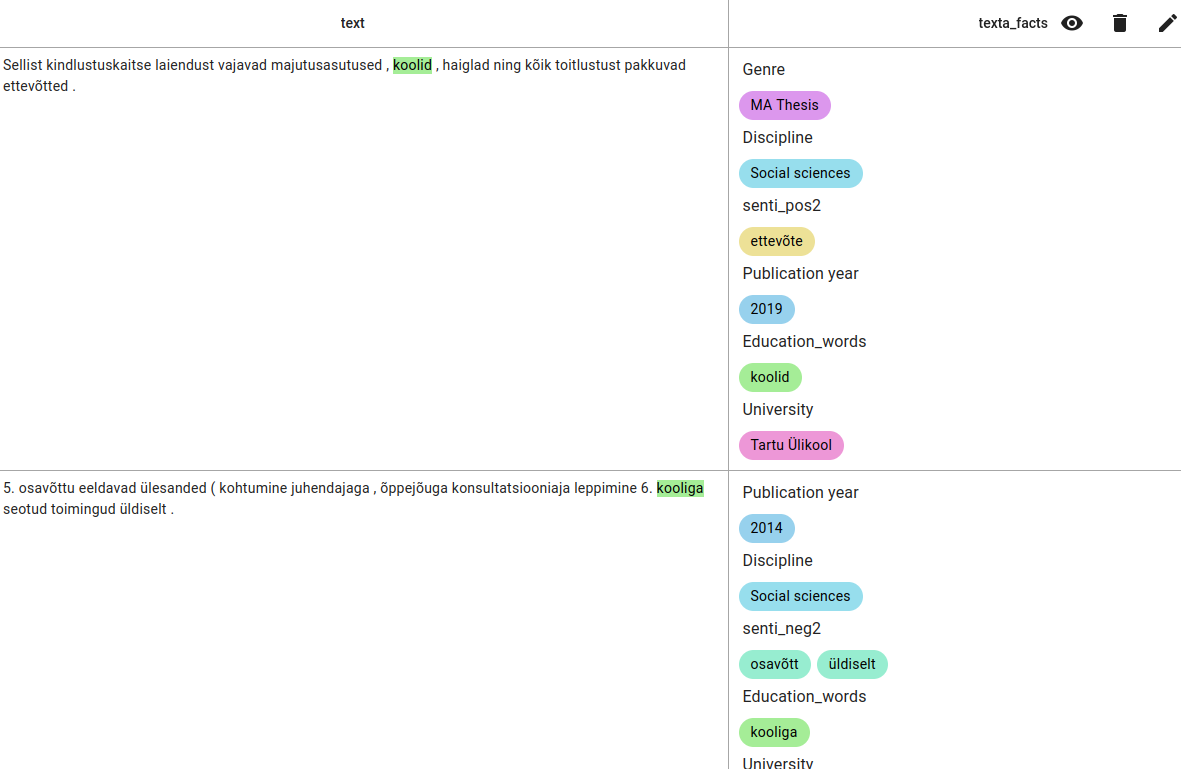
The results.
Keyword Extraction and Tagger Groups¶
RaKUn Extractor and Search Fields Tagger¶
Let’s say you have a special field with keywords in the corpus for each document and you’d like to turn the keywords into accessible metadata.
The Search Fields Tagger takes keywords stored in a field and turns them into facts.
If you’d like to create these keywords based on a lexicon or by using an embedding, RaKUn Extractor extracts keywords to facts using either a lexicon or a FastText Embedding.
The RaKUn Extractor can be trained based on lexicons.
Create a lexicon or FastTextEmbedding first.
Create a new RaKUn Extractor task with editdistance as algorithm and using your lexicon.
If you have a FastText Embedding in the project, you have the option to use that as the algorithm.
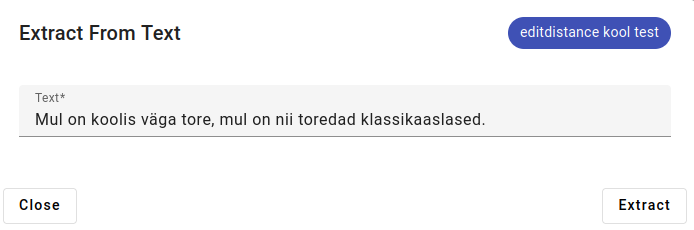
When the Extractor is trained, open up the Actions menu.
Example of using Extract from Text:
The result:
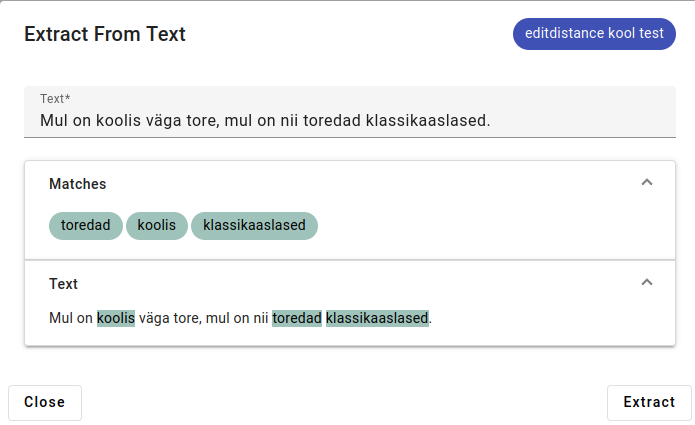
If applied to an index, RaKUn Extractor creates new facts based on the keywords it finds.
You can also add in more words to the lexicon (by clicking on Stop words in the actions menu) or change other parameters for potential improvements in the keyword results.
Tagger and Regex Tagger Groups¶
Tagger Group creates several Taggers (read more about Taggers here) at once based on a dataset with existing facts.
This allows you to use the facts for automatically tagging a new dataset.
An example use would be to train an index with discipline in facts and then applying the Tagger Group on another index to detect disciplines based on statistical and lexical similarity.
Regex Tagger Groups allows you to put together several Regex Taggers and apply them at once to multitag text.
Classification¶
CRF Extractors¶
If you have some data that has been annotated or some words that have already been extracted into facts using another tool, you could use CRF Extractors to apply this to a larger set of documents.
CRF or conditional random field is a statistical model.
Training a CRF model requires an index that has facts you want to use for finding the same features in another index. The facts you choose must be associated with a text_mlp field (for example text_mlp.lemmas or text_mlp.text). Besides the facts, you also need an embedding to find similar words.
To train a CRF model, go to Models and choose CRF Extractors.
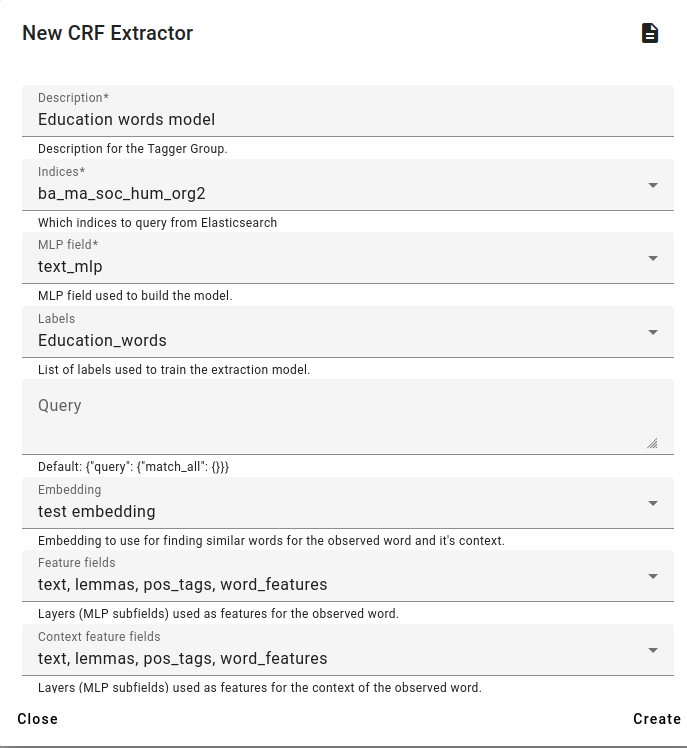
To train a CRF model, go to Models and choose CRF Extractors.
For this example, we use the Education_words fact generated by the regex tagger and the test embedding.

Choose the Feature fields which specifies which fields are used to generate features for the model and the Context feature fields that specifies which fields are used for context.
By default we will be using all the fields for extra linguistic information, but you can specify them as needed.
We can also specify the Feature extractors and Context Feature Extractors.
These include:
isupper - if word or context word occurs in uppercase or lowercase
istitle - if word or context word’s first letter is uppercase
hasdigit - word contains a number
strlength - takes the word length into account

There are also advanced settings, like setting the context window size, setting the test set size, changing the number of iterations, changing the class values or the suffix length. You can also change whether to use bias, which also considers the proportion of the word appearing in the training dataset.
Press Create.

Now the model is complete. We can see that the trained model’s F1, precision and recall has been evaluated based on the evaluation set size.
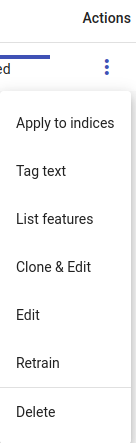
In the Actions menu you can apply the trained extractor to indices, Tag text, List Features, Clone & Edit, Edit (Rename), Retrain or Delete.
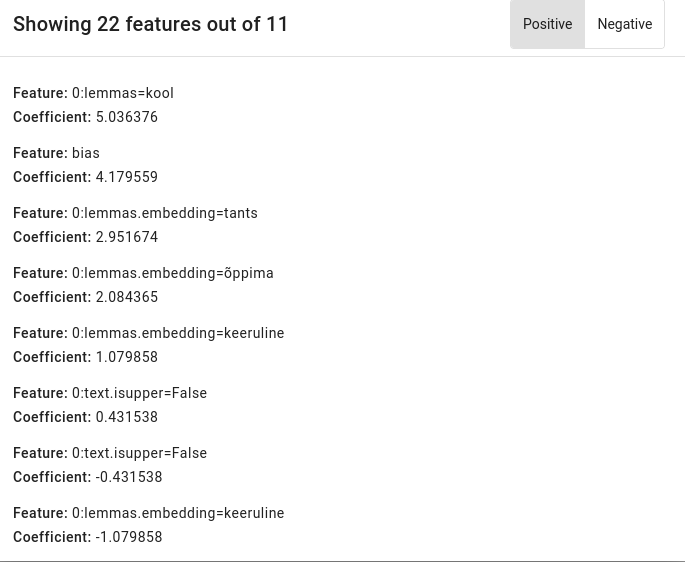
Using List Features, we can view the features associated with the keywords we chose before. For example, the most important feature for our educational words search is to find the lemma kool. Another important lemma is õppima.
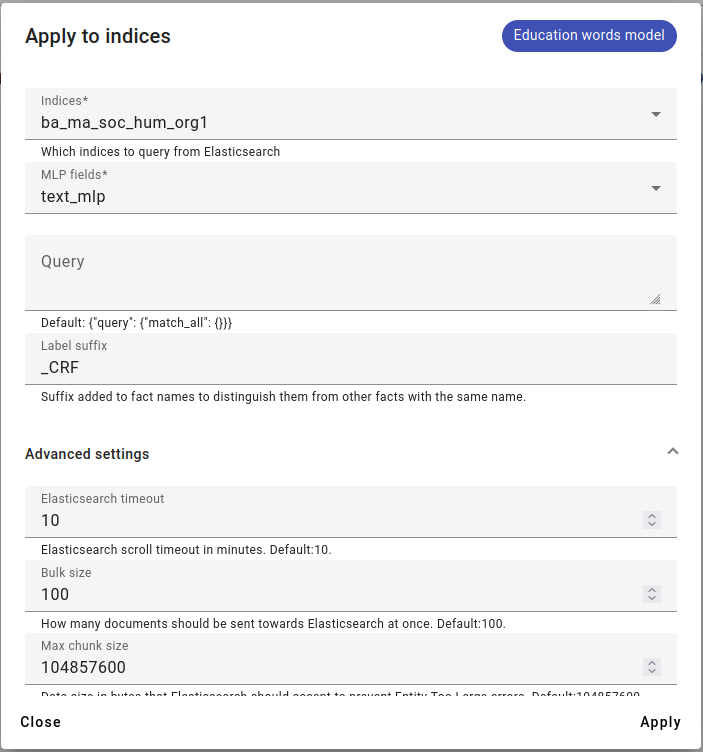
We apply CRF to an index that doesn’t have the Education fact. Choose the MLP fields (usually text_mlp) and the Label suffix (will be added to the fact name to differentiate from original fact).
You can also add a search query here if you only want the new fact to be created on some documents.
Press Apply.

Found words in the new index.
BERT Taggers¶
If we have a larger amount of documents with facts, we can train a BERT model to add the same facts to other indices based on the fact’s occurrence.
BERT taggers are usually trained to detect binary problems (problems with only two possible answers), whether something is true or not.
This means that BERT can be used for sentiment analysis or hate speech detection, for example.
BERT tagger uses a pre-trained large language model (which you can choose while training) so training the tagger is fine-tuning the selected model for a specific task. Read more about BERT here.
To create a BERT tagger, you should have an index with the facts you want to use for finding the same categories in another index.
To train a new BERT tagger, go to Models and click on BERT Taggers.
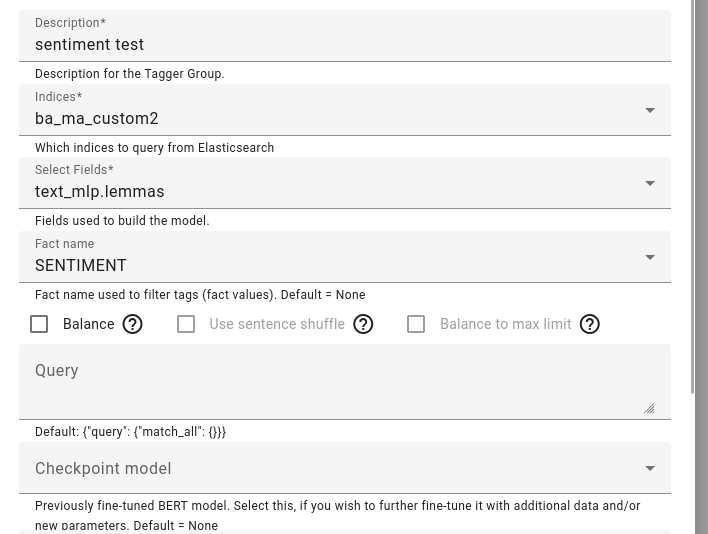
Choose the model description, the training indices and fields as well as the fact name to train on.
Add a query if you wish.
This task can also be used for further fine-tuning another BERT model.
Next choose an existing large language model (in the example above, the Estonian and Finnish BERT).
You can add pretrained models by clicking on Add pretrain model in the BERT Taggers menu and entering the huggingface.co model name (for example, the Finnish and Estonian BERT is at https://huggingface.co/EMBEDDIA/finest-bert).
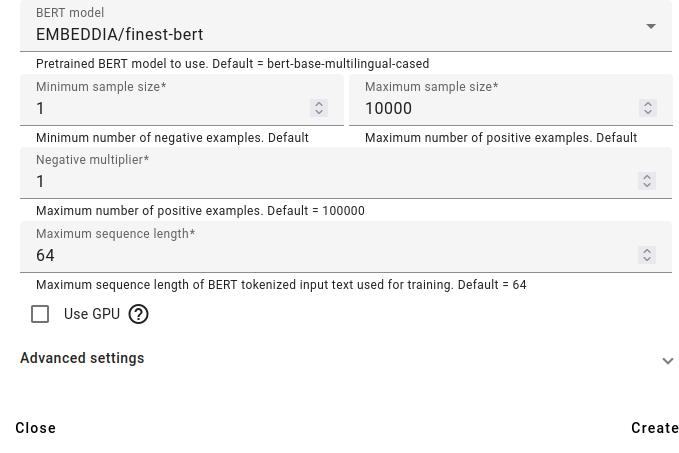
Select the minimum number of negative examples and the maximum number of positive examples, the negative multiplier and the maximum sequence length.
There is also an option to use GPU to make the training much faster, but since there is no GPU added to the Bwrite toolkit, this option is not available at the moment.
Press Create and wait for the model to train.
For a simple example tagging task, 50 documents were annotated with a sentiment fact that was either negative, positive or neutral as fact values.
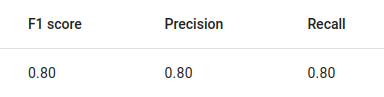
The F1, precision and recall scores of the BERT trained on the sentiment.

The number of examples was very small.
After training the BERT tagger, you have many options:
For data science and model improvement purposes you can look at Epoch reports and Confusion matrix.
You can apply the trained model to indices, tag text or tag a random document.
You can also edit (rename), retrain, clone & edit or delete the tagger task.
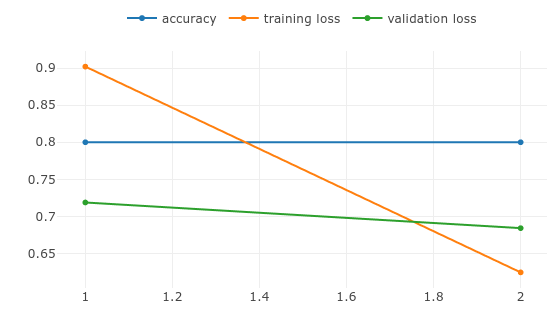
An example of epoch reports. This shows the accuracy, training loss and validation loss during training. These are metrics to evaluate machine learning models.
Tagging text example: simple.
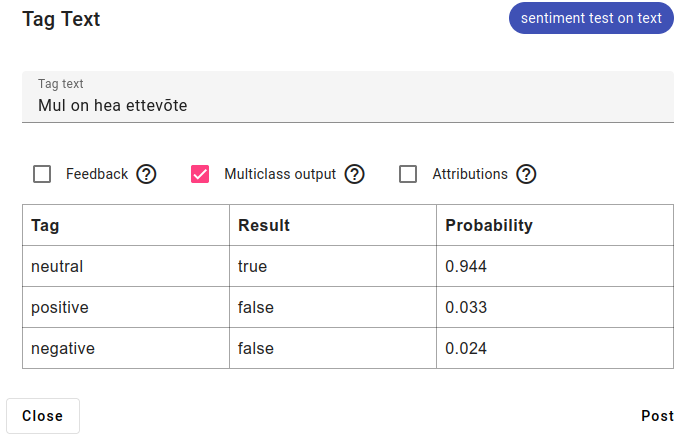
Tagging text example: multiclass output shows results for the other labels as well.

Tagging text example: getting attributions: reasoning what tokens or words BERT found to give this result.
Note
When applying or tagging with BERT tagger make sure that the fields don’t have a mismatch.
If you want to use BERT on regular (tokenized) text, then train it on regular text, not lemmas.
The mismatch can affect results.

An example of a confusion matrix. Usually (when training binary examples) a confusion matrix has only four boxes, showing Predicted label and True label intersection, which can be used to find what category the model works best on and what needs more or less examples.
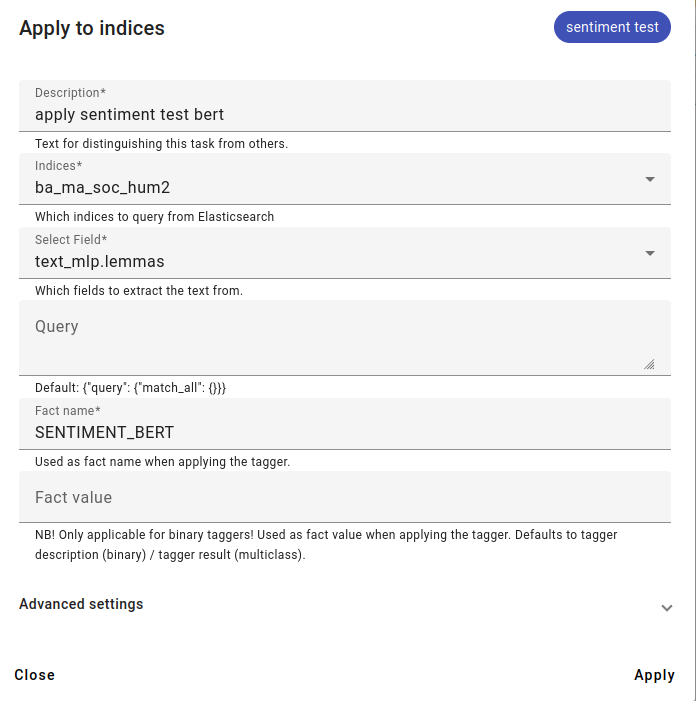
Applying the model to an index. Consider that applying the model will create new facts to the selected index.
The field selected should be as close to the trained BERT as possible (so if you train the model on lemmas, use should also be on lemmatized text).
Add a unique fact name, but leave fact value empty, the model can generate the fact name.

In this example, the facts BERT learned were not very useful, since all it learned was that most documents are neutral.
Given more training and test examples, it would be much more useful.
Taggers¶
Taggers work very similarly to BERT, but tagger uses a vectorizer and classifier.
Taggers are usually trained to detect binary problems (problems with only two possible answers), whether something is true or not.
Taggers are most useful for training on keywords or for topic modeling.
To create a Tagger, you should have an index with a fact you want to use for finding the same category in another index. You should also have an embedding to use.
Click on Taggers in the Models menu. Click Create.
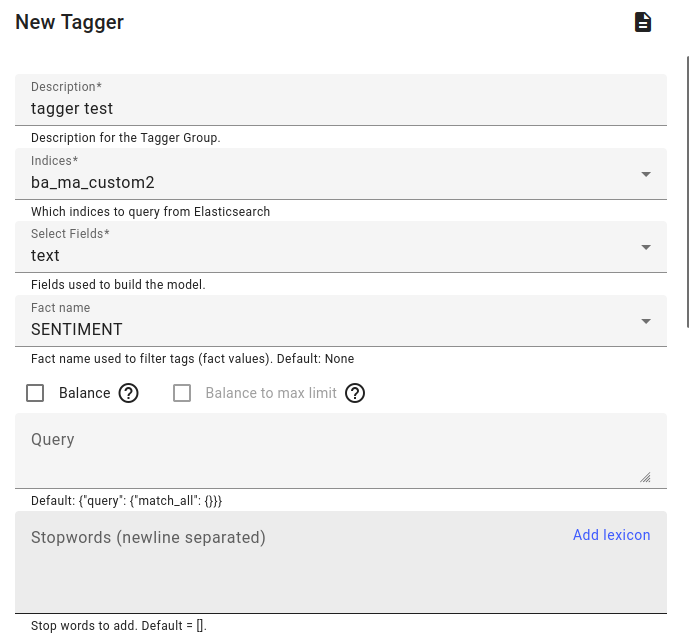
Fill in the description, the indices used for training, the field to train on and the fact name present in the index or indices.
Additional options are to balance the different labels in the facts.
You can also use a query or stopwords/lexicon.
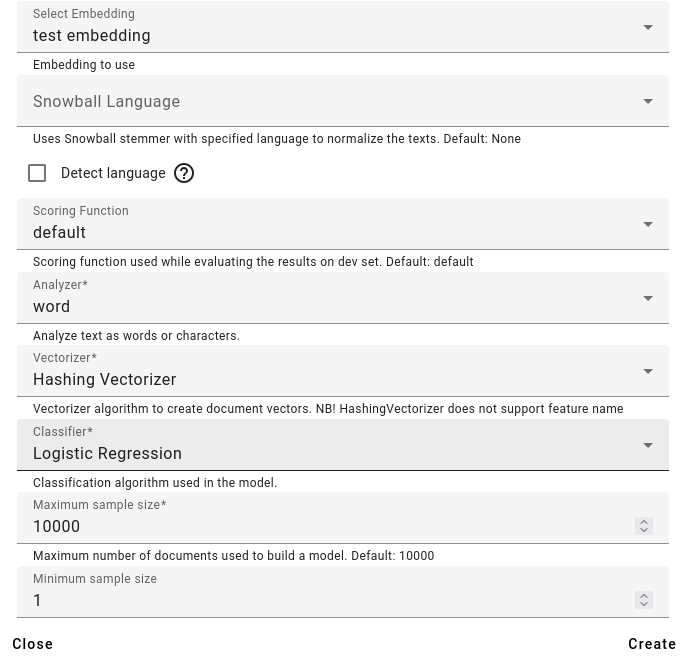
Select the embedding you wish to use.
You can also additionally use a snowball stemmer to normalize the texts, if you wish. If not and you want to use the stemmer, it would be good to use the Detect language option.
After this, select the scoring function, which is used while evaluating the results.
The options are:
default
precision
recall
f1_score
accuracy
jaccard
You can keep this at default if you don’t know which to choose.
Select the analyzer: if the text should be analyzed as words or characters.
Select the vectorizer and classifier. Basically you are choosing the algorithms to use. More information about these choices here: https://scikit-learn.org/stable/modules/feature_extraction.html.
Define the maximum and minimum size. If you have any facts that occur in less documents than the minimum, they won’t be used for training. The maximum is the amount of documents overall used for training (if you have any more, then only the maximum wil be used for training).
You can also use the negative multiplier if you wish.
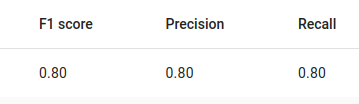
F1 results for the created Tagger.
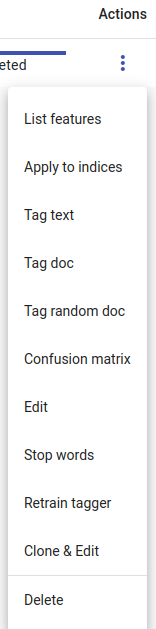
A list of actions for the Tagger task: we can list features (for example when training using the count vectorizer), apply to indices, tag text, tag doc, tag random doc, display confusion matrix, edit (rename task), add stop words, retrain tagger, clone & edit or delete task.
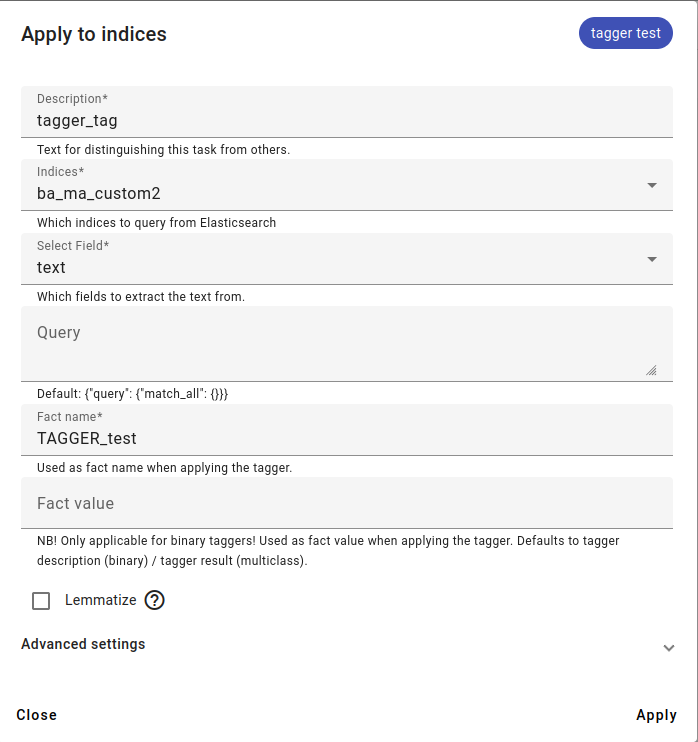
Applying the Tagger on an index.

Results are as expected, since an overwhelming amount of test data was neutral, Tagger has the same result.